Monocyte-derived transcriptome signature indicates antibody-dependent cellular phagocytosis as a potential mechanism of vaccine-induced protection against HIV-1
- ShidaShangguan12
- PhilipKEhrenberg1
- AvivaGeretz12
- LaurenYum12
- GautamKundu12
- KellyMay12
- SlimFourati3
- KrystelleNganou-Makamdop4
- LaTonyaDWilliams5
- SheetalSawant5
- EricLewitus12
- PunneePitisuttithum6
- SorachaiNitayaphan7
- SuwatChariyalertsak8
- SupachaiRerks-Ngarm9
- MorganeRolland2
- DanielCDouek4
- PeterGilbert10
- GeorgiaDTomaras5
- NelsonLMichael1
- SandhyaVasan12
- RasmiThomas[email protected]1
- Research Article
- Microbiology and Infectious Disease
- HIV vaccine
- transcriptomics
- single cell
- CITE-seq
- vaccine efficacy
- ADCP
- Human
- Rhesus macaque
- publisher-id69577
- doi10.7554/eLife.69577
- elocation-ide69577
Abstract
A gene signature was previously found to be correlated with mosaic adenovirus 26 vaccine protection in simian immunodeficiency virus and simian-human immunodeficiency virus challenge models in non-human primates. In this report, we investigated the presence of this signature as a correlate of reduced risk in human clinical trials and potential mechanisms of protection. The absence of this gene signature in the DNA/rAd5 human vaccine trial, which did not show efficacy, strengthens our hypothesis that this signature is only enriched in studies that demonstrated protection. This gene signature was enriched in the partially effective RV144 human trial that administered the ALVAC/protein vaccine, and we find that the signature associates with both decreased risk of HIV-1 acquisition and increased vaccine efficacy (VE). Total RNA-seq in a clinical trial that used the same vaccine regimen as the RV144 HIV vaccine implicated antibody-dependent cellular phagocytosis (ADCP) as a potential mechanism of vaccine protection. CITE-seq profiling of 53 surface markers and transcriptomes of 53,777 single cells from the same trial showed that genes in this signature were primarily expressed in cells belonging to the myeloid lineage, including monocytes, which are major effector cells for ADCP. The consistent association of this transcriptome signature with VE represents a tool both to identify potential mechanisms, as with ADCP here, and to screen novel approaches to accelerate the development of new vaccine candidates.
Introduction
The only HIV vaccine in ongoing human efficacy trials employs an adenovirus serotype 26 (Ad26)-based vector, but tests a different route of infection and geographic population compared to African women in whom it failed to show efficacy bib30bib35bib37. Vaccines from these trials were previously tested in non-human primates (NHPs) and showed partial protection from infection bib8bib9. To date, the pivotal RV144 phase three human efficacy trial conducted in Thailand is the only vaccine to show any protection against HIV bib43. This vaccine used a canary-pox ALVAC-based vector with a bivalent gp120 protein boost. Although neither of the vaccine regimens using Ad26 or canary-pox viral vectors were fully efficacious, there is some consensus that current preventive and treatment methods along with a moderately effective vaccine could potentially reduce the HIV pandemic bib4bib5bib17bib29. While a number of correlates of vaccine protection have been described for these studies, protection mediated by the humoral immune systems, including HIV-1 specific IgG antibody titers, antibody Fc polyfunctionality, antibody interactions with HLA class II gene products, and antibody effector functions, has been key features of these partially effective vaccines bib8bib9bib24bib41.
We previously showed that a vaccine-induced gene signature identified in B cells by an unbiased transcriptome-wide RNA-seq approach associated with decreased risk against simian immunodeficiency virus (SIV)/simian-human immunodeficiency virus (SHIV) infection in NHP studies evaluating the Ad26 vaccine bib16. This geneset was also enriched in NHP and the human RV144 trial that employed a vaccine containing the ALVAC viral vector bib16. This gene signature is not merely a general response elicited by vaccination, as it was not enriched in the Ad26-MVA arm of the SHIV challenge in NHP that showed some protection previously bib9. This gene signature was initially defined when comparing differentially expressed genes (DEGs) between B cells and monocytes from vaccinated individuals in an Influenza immunogenicity trial bib33. The geneset that was submitted to the molecular signature database (MSigdb) comprised the top 200 genes that were upregulated in monocytes compared to B cells. In our previous study, specific genes in this geneset were upregulated in the uninfected compared to the infected group in multiple SIV/HIV trials bib16. Genes that were previously correlated with immunogenicity in human vaccine trials of influenza and yellow fever, including TNFSF13 (APRIL), were also enriched in uninfected rhesus monkeys in the NHP studies bib28bib33. Although we first identified this geneset in sorted B cells bib16, we were able to identify the same signature associating with reduced infection in published microarray data sets from both bulk unstimulated and in vitro antigen-stimulated PBMC from three independent preclinical and clinical studies bib19bib56bib55. To determine if specific immune responses might be driving protection in conjunction with the gene signature, we examined whether this geneset associated with these responses measured in the NHP studies. We observed that this gene signature was also enriched in animals with the increased magnitude of ADCP bib16. We propose that this gene signature is a correlate of reduced risk of infection in efficacy studies and that further investigation of the enriched genes in the geneset could potentially help uncover the mechanism of vaccine protection. Here, we investigate this gene signature further as a proxy of vaccine-induced protection in human clinical trials to identify the cellular origin, as well as to investigate potential mechanisms for the decreased risk of infection.
Results
Gene signature is absent in a human HIV vaccine trial that did not show efficacy
Since the gene signature associated with protection within the vaccinated group in multiple studies from different sources and regimens, we wanted to further confirm that this signature was truly associated with protection by looking for its presence or absence in a human vaccine trial that failed to show efficacy (Supplementary file 1a). We screened for this gene signature in whole-transcriptome data within participants vaccinated with the DNA/rAd5 HIV-1 preventive vaccine in the HVTN 505 human efficacy trial. Immunizations in this trial were halted prior to reaching the clinical endpoint due to lack of efficacy bib23. When comparing infection status within vaccinated individuals, enrichment of this gene signature, as defined by the normalized enrichment score (NES), was not significant in transcriptome data from sorted B cells or monocytes 1 month after the final immunization (NES=–1.18, p=0.09 and NES=1.12, p=0.18, respectively). This finding further supports our hypothesis that this gene signature is associated with protection, as summarized in Table 1.
| Study | Vaccine regimen | Species | Partial protection | N | Method | Protective signature |
|---|---|---|---|---|---|---|
| 09–11 | Ad26/gp140 | NHP | Y | 10 | RNA-seq | Y |
| 13–19 | Ad26/gp140 | NHP | Y | 11 | RNA-seq | Y |
| 13–19 | A26/Ad26+ gp140 | NHP | Y | 12 | RNA-seq | Y |
| 13–19 | Ad26/MVA+ gp140 | NHP | Y | 9 | RNA-seq | N |
| ALVAC-SIV/gp120 | NHP | Y | 27 | Microarray | Y | |
| DNA-SIV/ALVAC+ gp120 | NHP | Y | 12 | Microarray | Y | |
| RV144 | ALVAC/gp120 | Human | Y | 170 | Microarray | Y |
| HVTN 505 | DNA/rAd5 | Human | N | 42 | RNA-seq | N |
Genes from this signature are the strongest correlate of protection in RV144
In previous analyses of NHP preclinical studies, we utilized a composite gene expression score (GES) consisting of an average of standardized expression of the specific number of enriched genes in one study to predict infection status in an independent study using the overlapping expressed genes from the first study bib16. While this method is successful in evaluating gene signatures in studies using similar vaccine strategies, we wanted to explore this approach across different studies using diverse platforms. For each independent study, we computed a GES derived from genes within the geneset that were enriched in uninfected donors by averaging standardized expression and showed that it associates with decreased HIV-1 infection (Figure 1). The magnitude of the GES and total number of enriched genes present in the gene signature are specific to each study and are higher in the uninfected compared to infected animals in the two NHP preclinical trials evaluating the mosaic Ad26 vaccine (09–11 and 13–19), including the different arms of the 13–19 study (13–19 a-b) (Figure 1A–C). Further, in the RV144 trial, the GES of 63 enriched genes in the gene signature also was higher in the vaccinated individuals that remained uninfected (Figure 1D). The number of enriched genes in each study might vary due to global differences in the vaccine strategies, but we consistently observed that higher GES associated with protection from HIV acquisition. We took advantage of the composite GES measurement to compare it with the other known primary correlates of HIV-1 infection risk in the human RV144 trial. IgG antibodies binding to the variable regions 1–2 (V1V2) of the HIV-1 Envelope (Env) have been shown to correlate with decreased risk of infection, while IgA binding to Env associated with increased risk of infection bib24. We show that the association of the GES in RV144 is a stronger correlate of reduced risk of infection than the previously described V1V2-specific IgG antibodies (Figure 2A). Cumulative incidence curves of HIV-1 infection showed decreased rates of infection among vaccine recipients with high GES (Figure 2B). Estimated vaccine efficacy (VE) was higher among vaccine recipients with higher GES (Figure 2C). The distribution of area under the receiver operating characteristic curve (AUC) and accuracy suggested that GES was also able to predict HIV-1 infection (Figure 2D). The effect of GES was also tested in RV144 vaccine and placebo participants who became infected during the trial bib45. If the GES was associated with VE, we would expect that vaccinees with a high GES would not get infected, hence vaccinees who became infected should have lower GES than placebo participants (who reflect the entire distribution of GES). This was observed across 43 breakthrough participants, with a significant difference among participants infected with single HIV-1 founder variants (N=29) (Figure 2—figure supplement 1). These findings strengthen the hypothesis that the GES is associated with VE.
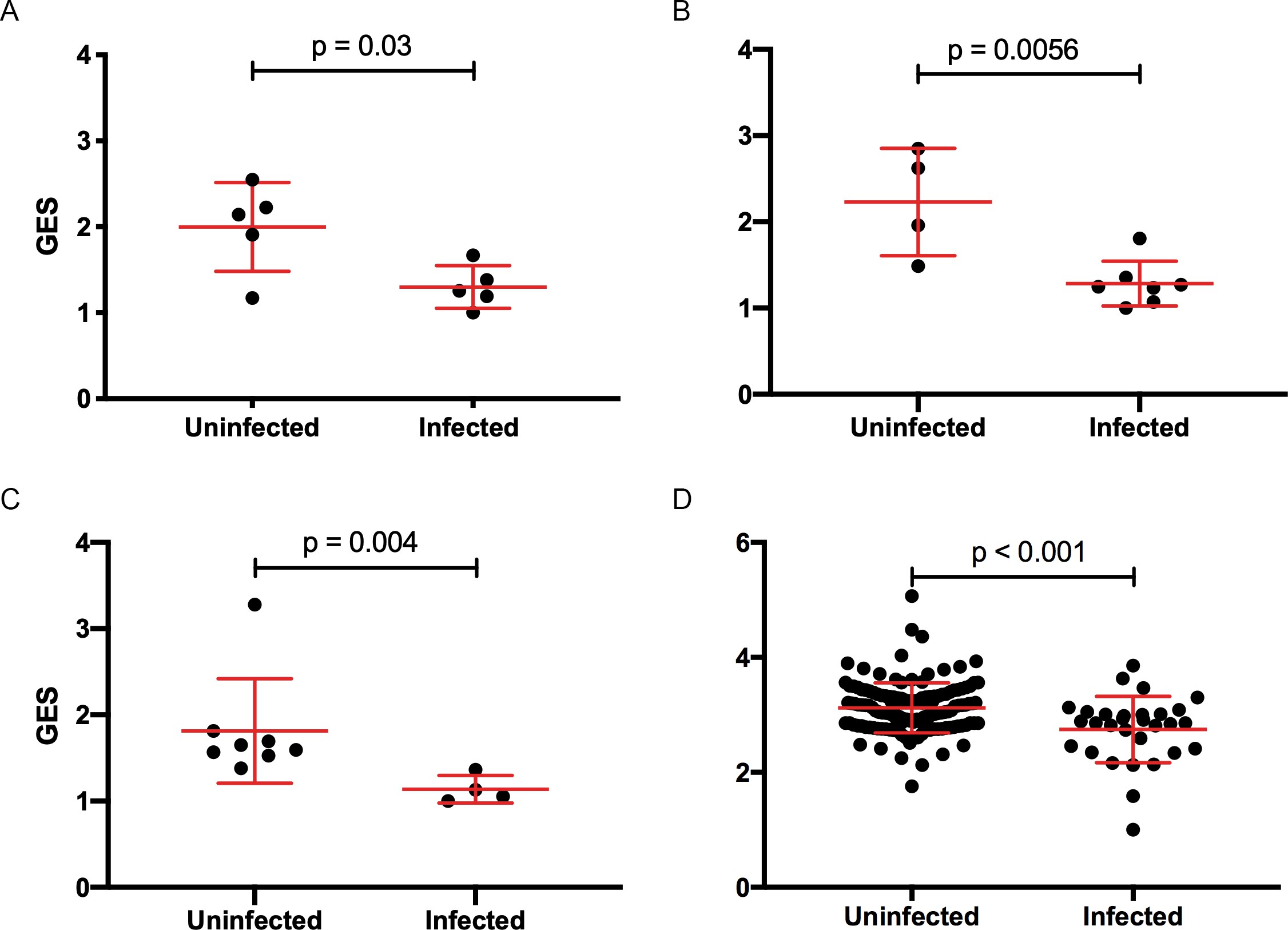
Composite gene expression scores (GES) are higher in the uninfected compared to infected groups.
GES computed from enriched genes in the geneset is higher in the uninfected compared to infected vaccinated NHP and humans. (A) Ad26/gp140 (09–11 NHP SIV challenge study, 58 enriched genes, N=10), (B) Ad26/gp140 (13–19 NHP SHIV challenge study, 58 enriched genes, N=11), (C) Ad26/Ad26+ gp140 (13–19 NHP SHIV challenge study, 68 enriched genes, N=12), and (D) ALVAC/gp 120 (RV144 human efficacy trial, 63 enriched genes, N=170). Statistical significance was calculated by either Mann-Whitney or unpaired t-test. NHP, non-human primate; SHIV, simian-human immunodeficiency virus; SIV, simian immunodeficiency virus.
library(ggplot2)
library(knitr)
library(plyr)
library(tidyverse)
library(cowplot)
library(magrittr)
library(dplyr)
library(readxl)
library(osDesign)
library(gplots)
library(rockchalk)
library(varhandle)
library(lattice)
library(forestplot)
library(survival)
library(fmsb)
library(InformationValue)
library(caret)
library(verification)
library(ROCR)
library(pROC)
library(extrafont)
library(huxtable)
library(Seurat)
library(ggvenn)
library(pheatmap)
library(ggplotify)
opts_chunk$set(tidy.opts=list(width.cutoff=55),tidy=TRUE)
load("Data/RV144 GES Analysis.RData")
flrstatus <- ifelse(mydata_rv144_vac_enriched63_170$infect=="Yes",1,0)
sex <-ifelse(mydata_rv144_vac_enriched63_170$dem_sex=="Female",1,0)
risk.cat <-ifelse(mydata_rv144_vac_enriched63_170$BRA_risk=="Low",0,ifelse(mydata_rv144_vac_enriched63_170$BRA_risk=="Medium",1,2))
risk.medium <- ifelse(mydata_rv144_vac_enriched63_170$BRA_risk=="Medium",1,0)
risk.high <- ifelse(mydata_rv144_vac_enriched63_170$BRA_risk=="High",1,0)
EIGEN1 <- mydata_rv144_vac_enriched63_170$EIGEN1
# making GES using scaled gene expression data (the enriched 63 genes)
trans63= rowMeans(mydata_rv144_vac_enriched63_170[,64:126])
####################### two phase design ##############################
nn0 <- c(length(dat1$pin[dat1$infect=="No" & dat1$cc_cohort==1 & dat1$trt=="VACCINE" & dat1$dem_sex=="Female" & dat1$perprot=="Yes" & dat1$vaccno==4]),
length(dat1$pin[dat1$infect=="No" & dat1$cc_cohort==1 & dat1$trt=="VACCINE" & dat1$dem_sex=="Male" & dat1$perprot=="Yes" & dat1$vaccno==4]),
length(dat1$pin[dat1$infect=="No" & dat1$cc_cohort==1 & dat1$trt=="VACCINE" & dat1$dem_sex=="Female" & dat1$perprot=="No" & dat1$vaccno==4]),
length(dat1$pin[dat1$infect=="No" & dat1$cc_cohort==1 & dat1$trt=="VACCINE" & dat1$dem_sex=="Male" & dat1$perprot=="No" & dat1$vaccno==4]),
length(dat1$pin[dat1$infect=="No" & dat1$cc_cohort==1 & dat1$trt=="VACCINE" & dat1$dem_sex=="Female" & dat1$perprot=="No" & dat1$vaccno<4]))
nn1 <- c(length(dat1$pin[dat1$infect=="Yes" & dat1$cc_cohort==1 & dat1$trt=="VACCINE" & dat1$dem_sex=="Female" & dat1$perprot=="Yes" & dat1$vaccno==4]),
length(dat1$pin[dat1$infect=="Yes" & dat1$cc_cohort==1 & dat1$trt=="VACCINE" & dat1$dem_sex=="Male" & dat1$perprot=="Yes" & dat1$vaccno==4]),
length(dat1$pin[dat1$infect=="Yes" & dat1$cc_cohort==1 & dat1$trt=="VACCINE" & dat1$dem_sex=="Female" & dat1$perprot=="No" & dat1$vaccno==4]),
length(dat1$pin[dat1$infect=="Yes" & dat1$cc_cohort==1 & dat1$trt=="VACCINE" & dat1$dem_sex=="Male" & dat1$perprot=="No" & dat1$vaccno==4]),
length(dat1$pin[dat1$infect=="Yes" & dat1$cc_cohort==1 & dat1$trt=="VACCINE" & dat1$dem_sex=="Female" & dat1$perprot=="No" & dat1$vaccno<4]))
stratuminds <- ifelse(mydata_rv144_vac_enriched63_170$dem_sex=="Female" & mydata_rv144_vac_enriched63_170$perprot=="Yes" & mydata_rv144_vac_enriched63_170$vaccno==4,1,
ifelse(mydata_rv144_vac_enriched63_170$dem_sex=="Male" & mydata_rv144_vac_enriched63_170$perprot=="Yes" & mydata_rv144_vac_enriched63_170$vaccno==4,2,
ifelse(mydata_rv144_vac_enriched63_170$dem_sex=="Female" & mydata_rv144_vac_enriched63_170$perprot=="No" & mydata_rv144_vac_enriched63_170$vaccno==4,3,
ifelse(mydata_rv144_vac_enriched63_170$dem_sex=="Male" & mydata_rv144_vac_enriched63_170$perprot=="No" & mydata_rv144_vac_enriched63_170$vaccno==4,4,5))))
scaled_trans63=scale(trans63)
fit.tps <- tps(flrstatus ~ scaled_trans63 + EIGEN1 + sex+ risk.medium+ risk.high,nn0=nn0, nn1=nn1,group=stratuminds,method="ML",cohort=TRUE)
x <- as.matrix(cbind(round(exp(fit.tps$coef[2]),2),round(exp(fit.tps$coef[2] - sqrt(fit.tps$covm[2,2])*1.96),2),
round(exp(fit.tps$coef[2] + sqrt(fit.tps$covm[2,2])*1.96),2),round(min(2*(1-pnorm(abs(fit.tps$coef[2]/sqrt(fit.tps$covm[2,2])))),1.0)
,4)))
colnames(x)=c("OR","95%CI LB","95%CI UB", "p value")
rownames(x)="GES"
x
myforest=matrix(NA, 3, 4)
rownames(myforest)=c("GES","gp70-V1V2 (IgG)", "IgA (Env)")
myforest=as.data.frame(myforest)
colnames(myforest)=c("OR","95%CI LB","95%CI UB","p value")
myforest[1,]=c(0.37,0.22,0.63,"0.0002")
myforest[2,]=c(0.7,0.49,1.02,0.06)
myforest[3,]=c(1.39,1.00,1.93,0.05)
tabletext <- cbind(c("Immune Response",rownames(myforest)),
c("p value",myforest$`p value`))
forestplot(labeltext=tabletext, graph.pos=2,
mean=c(NA,myforest$OR),
lower=c(NA,myforest$`95%CI LB`), upper=c(NA,myforest$`95%CI UB`),
txt_gp=fpTxtGp(label=gpar(cex=0.7),
ticks=gpar(cex=0.5),
xlab=gpar(cex = 0.7),
title=gpar(cex = 1.0)),
col=fpColors(box="black", lines="black", zero = "gray60"),
zero=1, lineheight = "auto", boxsize=0.11, colgap=unit(2.5,"mm"),
lwd.ci=2, ci.vertices=TRUE, ci.vertices.height = 0.05,xticks = c(0,0.25,0.5,0.75,1,1.25, 1.5, 1.75, 2.00), xlab="\n Odds Ratio")GES is associated with lower odds of HIV acquisition compared to the other two primary correlates of risk. Variables were measured at week 26, 2 weeks post last vaccination. For each variable, the OR is reported per 1-SD increase. Transcriptome data was available only in a subset of the 246 donors.
############## Cumulative Incidence Curve #####################
########### GES63 low med high #########
alpha1.0 <- length(unique(mydata_rv144_vac_enriched63_170$pin[mydata_rv144_vac_enriched63_170$trt=="VACCINE" & mydata_rv144_vac_enriched63_170$infect=="No" & mydata_rv144_vac_enriched63_170$dem_sex=="Female" & mydata_rv144_vac_enriched63_170$perprot=="Yes" & mydata_rv144_vac_enriched63_170$vaccno==4]))/
length(dat1$pin[dat1$trt=="VACCINE" & dat1$infect=="No" & dat1$cc_cohort==1 & dat1$dem_sex=="Female" & dat1$perprot=="Yes" & dat1$vaccno==4])
alpha2.0 <- length(unique(mydata_rv144_vac_enriched63_170$pin[mydata_rv144_vac_enriched63_170$trt=="VACCINE" & mydata_rv144_vac_enriched63_170$infect=="No" & mydata_rv144_vac_enriched63_170$dem_sex=="Male" & mydata_rv144_vac_enriched63_170$perprot=="Yes" & mydata_rv144_vac_enriched63_170$vaccno==4]))/
length(dat1$pin[dat1$trt=="VACCINE" & dat1$infect=="No" & dat1$cc_cohort==1 & dat1$dem_sex=="Male" & dat1$perprot=="Yes" & dat1$vaccno==4])
alpha3.0 <- length(unique(mydata_rv144_vac_enriched63_170$pin[mydata_rv144_vac_enriched63_170$trt=="VACCINE" & mydata_rv144_vac_enriched63_170$infect=="No" & mydata_rv144_vac_enriched63_170$dem_sex=="Female" & mydata_rv144_vac_enriched63_170$perprot=="No" & mydata_rv144_vac_enriched63_170$vaccno==4]))/
length(dat1$pin[dat1$trt=="VACCINE" & dat1$infect=="No" & dat1$cc_cohort==1 & dat1$dem_sex=="Female" & dat1$perprot=="No" & dat1$vaccno==4])
alpha4.0 <- length(unique(mydata_rv144_vac_enriched63_170$pin[mydata_rv144_vac_enriched63_170$trt=="VACCINE" & mydata_rv144_vac_enriched63_170$infect=="No" & mydata_rv144_vac_enriched63_170$dem_sex=="Male" & mydata_rv144_vac_enriched63_170$perprot=="No" & mydata_rv144_vac_enriched63_170$vaccno==4]))/
length(dat1$pin[dat1$trt=="VACCINE" & dat1$infect=="No" & dat1$cc_cohort==1 & dat1$dem_sex=="Male" & dat1$perprot=="No" & dat1$vaccno==4])
alpha5.0 <- length(unique(mydata_rv144_vac_enriched63_170$pin[mydata_rv144_vac_enriched63_170$trt=="VACCINE" & mydata_rv144_vac_enriched63_170$infect=="No" & mydata_rv144_vac_enriched63_170$dem_sex=="Female" & mydata_rv144_vac_enriched63_170$perprot=="No" & mydata_rv144_vac_enriched63_170$vaccno<4]))/
length(dat1$pin[dat1$trt=="VACCINE" & dat1$infect=="No" & dat1$cc_cohort==1 & dat1$dem_sex=="Female" & dat1$perprot=="No" & dat1$vaccno<4])
cat63_3.vp <- as.factor(dat.vcc.allplc_3$cat63_3.vp)
flrtime.vp <- dat.vcc.allplc_3$time_to_infect - dat.vcc.allplc_3$time_to_wk26
flrstatus.vp <- ifelse(dat.vcc.allplc_3$infect=="Yes",1,0)
cat63.vp <- dat.vcc.allplc_3$cat63.vp
IGG.vp <- dat.vcc.allplc_3$IGG.vp
IGG_DPB13.vp <- dat.vcc.allplc_3$IGG_DPB13.vp
DPB13.vp <- dat.vcc.allplc_3$DPB13.vp
wt <- ifelse(flrstatus.vp ==1 |dat.vcc.allplc_3$trt=="PLACEBO",1,
ifelse(dat.vcc.allplc_3$trt=="VACCINE" & flrstatus.vp==0 & dat.vcc.allplc_3$dem_sex=="Female" & dat.vcc.allplc_3$perprot=="Yes" &
dat.vcc.allplc_3$vaccno==4,1/alpha1.0,
ifelse(dat.vcc.allplc_3$trt=="VACCINE" & flrstatus.vp==0 & dat.vcc.allplc_3$dem_sex=="Male" & dat.vcc.allplc_3$perprot=="Yes" &
dat.vcc.allplc_3$vaccno==4,1/alpha2.0,
ifelse(dat.vcc.allplc_3$trt=="VACCINE" & flrstatus.vp==0 & dat.vcc.allplc_3$dem_sex=="Female" & dat.vcc.allplc_3$perprot=="No" &
dat.vcc.allplc_3$vaccno==4,1/alpha3.0,
ifelse(dat.vcc.allplc_3$trt=="VACCINE" & flrstatus.vp==0 & dat.vcc.allplc_3$dem_sex=="Male" & dat.vcc.allplc_3$perprot=="No" &
dat.vcc.allplc_3$vaccno==4,1/alpha4.0,1/alpha5.0)))))
###################################################
# KM plots by GES (low vs. med vs. high)
output.legend <- NULL
scl <- 365.25/12
new <- cat63_3.vp
levels(new)=c("0","3","1","2")
new = factor(new,levels(new)[c(1,3,4,2)])
V1=new
par(mfrow=c(1,1),mar=c(5,4,2,3),las=1,cex.axis=1.1,cex.lab=1.1,cex.main=1.1,oma=c(4,2,0,0))
KM <- survfit(Surv(flrtime.vp/scl, flrstatus.vp)~V1, type="kaplan-meier",weights=wt)
sKM <- summary(KM,times=c(0,12,24,36,48),extend=T)
n.events.total <- tapply(sKM$n.event,rep(1:5,each=4),sum)
n.event <- matrix(round(sKM$n.event),nrow=4,byrow=T)
n.atrisk <- matrix(round(sKM$n.risk),nrow=4,byrow=T)
ptime <- unique(sKM$time)
output.legend <- data.frame(Variable=rep("GES63",8),Type=rep(c("n.atrisk","n.event"),each=4),
Category=rep(c("Placebo","Low GES","Medium GES","High GES"),2),rbind(n.atrisk,n.event))
plot(KM,fun="event",col=c("black","red","blue","purple4"),lty=c(1,1,1,1),xlab="Months since the week 26 visit",ylab="",lwd=4.7,axes=F,xlim=c(0,40),mark.time=TRUE)
#str(V1)
legend(0, .0075, c("Placebo", "Low GES","Medium GES","High GES"), lty=c(1,1,1,1),lwd=c(2,2,2),col=c("black","red","blue","purple4"),bty="n",cex=0.8,y.intersp=0.8)
box(bty="l")
axis(1,at=seq(0,40,by=12),label=c("0","12","24","36"))
axis(2,at=seq(0,0.01,by=0.002),label=c( "0.000", "0.002", "0.004", "0.006", "0.008"," 0.010"))
mtext(side=1,at=-10,text="Number at risk:",line=4,cex=1.0,adj=0)
mtext(side=1,at=-10,text="Placebo",line=5,cex=1.0,adj=0)
mtext(side=1,at=-10,text="Low GES",line=6,cex=1.0,adj=0)
mtext(side=1,at=-10,text="Medium GES",line=7,cex=1.0,adj=0)
mtext(side=1,at=-10,text="High GES",line=8,cex=1.0,adj=0)
mtext(side=1,text=n.atrisk[1,],line=5,at=ptime,cex=1.0)
mtext(side=1,text=n.atrisk[2,],line=6,at=ptime,cex=1.0)
mtext(side=1,text=n.atrisk[3,],line=7,at=ptime,cex=1.0)
mtext(side=1,text=n.atrisk[4,],line=8,at=ptime,cex=1.0)
mtext(side=1,text=paste("(",n.event[1,],")"),line=5,at=ptime+3,cex=0.9)
mtext(side=1,text=paste("(",n.event[2,],")"),line=6,at=ptime+3,cex=0.9)
mtext(side=1,text=paste("(",n.event[3,],")"),line=7,at=ptime+3,cex=0.9)
mtext(side=1,text=paste("(",n.event[4,],")"),line=8,at=ptime+3,cex=0.9)
mtext(side=2,"Probability of acquiring HIV-1 infection",cex=1.1,outer=T,las=3,line=1)
Probability of acquiring HIV-1 is lower in individuals with higher GES.
flrtime.vp <- dat.vcc.allplc_3$time_to_infect - dat.vcc.allplc_3$time_to_wk26
flrstatus.vp <- ifelse(dat.vcc.allplc_3$infect=="Yes",1,0)
sex.vp <- ifelse(dat.vcc.allplc_3$dem_sex=="Female",1,0)
risk.cat.vp <- ifelse(dat.vcc.allplc_3$BRA_risk=="Low",0,ifelse(dat.vcc.allplc_3$BRA_risk=="Medium",1,2))
risk.medium.vp <- ifelse(dat.vcc.allplc_3$BRA_risk=="Medium",1,0)
risk.high.vp <- ifelse(dat.vcc.allplc_3$BRA_risk=="High",1,0)
############# two-phase design ################
nn0.vp <- c(length(dat1$pin[dat1$infect=="No" & dat1$cc_cohort==1 & dat1$trt=="VACCINE" & dat1$dem_sex=="Female" & dat1$perprot=="Yes" & dat1$vaccno==4]),
length(dat1$pin[dat1$infect=="No" & dat1$cc_cohort==1 & dat1$trt=="VACCINE" & dat1$dem_sex=="Male" & dat1$perprot=="Yes" & dat1$vaccno==4]),
length(dat1$pin[dat1$infect=="No" & dat1$cc_cohort==1 & dat1$trt=="VACCINE" & dat1$dem_sex=="Female" & dat1$perprot=="No" & dat1$vaccno==4]),
length(dat1$pin[dat1$infect=="No" & dat1$cc_cohort==1 & dat1$trt=="VACCINE" & dat1$dem_sex=="Male" & dat1$perprot=="No" & dat1$vaccno==4]),
length(dat1$pin[dat1$infect=="No" & dat1$cc_cohort==1 & dat1$trt=="VACCINE" & dat1$dem_sex=="Female" & dat1$perprot=="No" & dat1$vaccno<4]),
length(dat1$pin[dat1$infect=="No" & dat1$cc_cohort==1 & dat1$trt=="PLACEBO" & (dat1$time_to_infect > dat1$time_to_wk26)])
)
nn1.vp <- c(length(dat1$pin[dat1$infect=="Yes" & dat1$cc_cohort==1 & dat1$trt=="VACCINE" & dat1$dem_sex=="Female" & dat1$perprot=="Yes" & dat1$vaccno==4]),
length(dat1$pin[dat1$infect=="Yes" & dat1$cc_cohort==1 & dat1$trt=="VACCINE" & dat1$dem_sex=="Male" & dat1$perprot=="Yes" & dat1$vaccno==4]),
length(dat1$pin[dat1$infect=="Yes" & dat1$cc_cohort==1 & dat1$trt=="VACCINE" & dat1$dem_sex=="Female" & dat1$perprot=="No" & dat1$vaccno==4]),
length(dat1$pin[dat1$infect=="Yes" & dat1$cc_cohort==1 & dat1$trt=="VACCINE" & dat1$dem_sex=="Male" & dat1$perprot=="No" & dat1$vaccno==4]),
length(dat1$pin[dat1$infect=="Yes" & dat1$cc_cohort==1 & dat1$trt=="VACCINE" & dat1$dem_sex=="Female" & dat1$perprot=="No" & dat1$vaccno<4]),
length(dat1$pin[dat1$infect=="Yes" & dat1$cc_cohort==1 & dat1$trt=="PLACEBO" & (dat1$time_to_infect > dat1$time_to_wk26)]))
stratuminds.vp <- ifelse(dat.vcc.allplc_3$trt=="VACCINE" & dat.vcc.allplc_3$dem_sex=="Female" & dat.vcc.allplc_3$perprot=="Yes" & dat.vcc.allplc_3$vaccno==4,1,
ifelse(dat.vcc.allplc_3$trt=="VACCINE" & dat.vcc.allplc_3$dem_sex=="Male" & dat.vcc.allplc_3$perprot=="Yes" & dat.vcc.allplc_3$vaccno==4,2,
ifelse(dat.vcc.allplc_3$trt=="VACCINE" & dat.vcc.allplc_3$dem_sex=="Female" & dat.vcc.allplc_3$perprot=="No" & dat.vcc.allplc_3$vaccno==4,3,
ifelse(dat.vcc.allplc_3$trt=="VACCINE" & dat.vcc.allplc_3$dem_sex=="Male" & dat.vcc.allplc_3$perprot=="No" & dat.vcc.allplc_3$vaccno==4,4,
ifelse(dat.vcc.allplc_3$trt=="VACCINE" & dat.vcc.allplc_3$dem_sex=="Female" & dat.vcc.allplc_3$perprot=="No" & dat.vcc.allplc_3$vaccno<4,5,6)))))
fit.tps.vp.cat63 <- tps(flrstatus.vp ~ factor(new) + sex.vp + risk.medium.vp + risk.high.vp,nn0=nn0.vp,
nn1=nn1.vp,group=stratuminds.vp,method="ML",cohort=TRUE, data=dat.vcc.allplc_3)
out1 <- fit.tps.vp.cat63$coef
out2 <- diag(fit.tps.vp.cat63$covm)
I = 2
q = t(fit.tps.vp.cat63$coef[I])%*%solve(fit.tps.vp.cat63$covm[c(I),c(I)])%*%fit.tps.vp.cat63$coef[I]
p.one = 1 - pchisq(q, 1)
I = 3
q = t(fit.tps.vp.cat63$coef[I])%*%solve(fit.tps.vp.cat63$covm[c(I),c(I)])%*%fit.tps.vp.cat63$coef[I]
p.two = 1 - pchisq(q, 1)
I = 4
q = t(fit.tps.vp.cat63$coef[I])%*%solve(fit.tps.vp.cat63$covm[c(I),c(I)])%*%fit.tps.vp.cat63$coef[I]
p.three = 1 - pchisq(q, 1)
par(mar=c(3.5, 5, 2.1, 2.1), bty="l")
plotCI(x=1-exp(out1[2:4]),ui= 1-exp(out1[2:4] - 1.96*sqrt(out2[2:4])), li= 1-exp(out1[2:4] + 1.96*sqrt(out2[2:4])),
col=c("red","blue","purple4"), barcol=c("red","blue","purple4"), lwd=3, xaxt="n", yaxt="n", xlab="", ylab="",
xlim=c(0.25, 3.55), ylim=c(-2,1), cex.lab=1.4, cex.main=1.4)
axis(2, at=seq(-2,1,by=0.5), labels=paste(seq(-200,100,by=50), "%", sep=""), lwd.ticks=2, tcl=-0.6, las=2, cex.axis=1.1)
axis(2, at=seq(-2,1,by=0.1), labels=NA, cex.axis=1.1, tcl=-0.4)
axis(side=1, at=1:3, labels=c("Low","Medium","High"), cex.axis=1.1)
abline(h=0,lty=2, col=2)
title(ylab="Estimated VE", cex.lab=1.2, line=4)
title(xlab="GES", cex.lab=1.2, line=2.2)
pvals = sapply(c(p.one, p.two,p.three), sprintf, fmt="p = %0.2f")
text(x=1:3, y=rep(0.98,1), pvals)
text(x=c(1.3,2.3,3.3), y=1-exp(out1[2:4]), paste(round(100*(1-exp(out1[2:4])),2),"%",sep=""))
text(x=c(1.3,2.3,3.3), y=1-exp(out1[2:4] - 1.96*sqrt(out2[2:4])), paste(round(100*(1-exp(out1[2:4] - 1.96*sqrt(out2[2:4]))),2),"%",sep=""))
text(x=c(1.3,2.3,3.3), y=1-exp(out1[2:4] + 1.96*sqrt(out2[2:4])), paste(round(100*(1-exp(out1[2:4] + 1.96*sqrt(out2[2:4]))),2),"%",sep=""))Vaccine efficacy is increased significantly in individuals with high GES.
######## repeat data partition 1000: caculate accuracy & auc #######
auc <- NULL
p_auc <- NULL
k <- 1000
acc <- NULL
cutp <- NULL
pbar <- create_progress_bar('text')
pbar$init(k)
set.seed(123)
for(i in 1:k)
{
# Train-test splitting
# 70% of samples -> training
# 30% of samples -> testing
trainIndex <- createDataPartition(mydata_rv144_vac_enriched63_170$infect, p = .7,
list = FALSE)
train <- mydata_rv144_vac_enriched63_170[trainIndex,]
test <- mydata_rv144_vac_enriched63_170[-trainIndex,]
flrstatus <- ifelse(test$infect=="Yes",1,0)
sex <-ifelse(test$dem_sex=="Female",1,0)
risk.cat <-ifelse(test$BRA_risk=="Low",0,ifelse(test$BRA_risk=="Medium",1,2))
risk.medium <- ifelse(test$BRA_risk=="Medium",1,0)
risk.high <- ifelse(test$BRA_risk=="High",1,0)
EIGEN1 <- test$EIGEN1
trans63=test$trans_63
test_data=as.data.frame(cbind(flrstatus,sex,risk.medium,risk.high,EIGEN1,trans63))
rownames(test_data)=rownames(test)
flrstatus <- ifelse(train$infect=="Yes",1,0)
sex <-ifelse(train$dem_sex=="Female",1,0)
risk.cat <-ifelse(train$BRA_risk=="Low",0,ifelse(train$BRA_risk=="Medium",1,2))
risk.medium <- ifelse(train$BRA_risk=="Medium",1,0)
risk.high <- ifelse(train$BRA_risk=="High",1,0)
EIGEN1 <- train$EIGEN1
trans63=train$trans_63
train_data=as.data.frame(cbind(flrstatus,sex,risk.medium,risk.high,EIGEN1,trans63))
rownames(train_data)=rownames(train)
model <- glm(flrstatus~trans63+ EIGEN1 + sex + risk.medium + risk.high,family = binomial(link = "logit"),data = train_data)
cutp <- optimalCutoff(actuals = train_data$flrstatus, predictedScores = predict(model, train_data, type="response"), optimiseFor = "misclasserror")
results_prob <- predict(model, test_data, type="response")
results <- ifelse(results_prob > cutp,1,0)
answers <- test_data$flrstatus
misClasificError <- mean(answers != results)
acc[i] <- 1-misClasificError
auc[i]=roc.area(answers,results_prob)$A
pbar$step()
}
hist(auc,
col="green4",
border="green4",
density=70,
probability = TRUE,
xlim = c(0.3,1),
ylim = c(0,15),
xlab = "",
breaks = 30,
main = "")
par(new=TRUE)
plot(density(acc, bw = 0.02), xlim = c(0.3,1),
ylim = c(0,15),main="",xlab="AUC & Accuracy",col="orange",lwd=2,bty="n")
legend(x=0.9,y=15, "AUC", fill="green4",density=70, border="green4",bty="n",cex = 0.8)
legend(x=0.9,y=14, "Accuracy", col="orange",lty = 1 ,lwd=2, seg.len=1, bty="n",cex = 0.8)Distribution of AUC and accuracy plotted after repeating the process 1000 times showed that GES could predict HIV-1 infection with AUC of 0.67±0.08 and with accuracy of 0.81±0.04. GES, gene expression score.
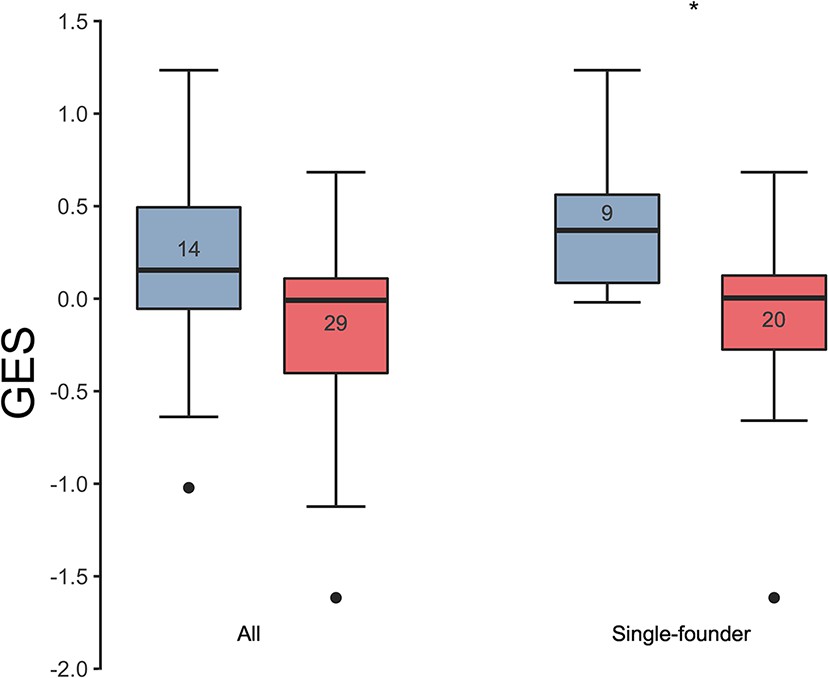
Association of the GES with HIV-1 breakthrough infections in a human vaccine trial.
GES was significantly higher in the placebo (blue) compared to vaccine recipients (red) among the RV144 participants with single-founder breakthrough infection (p<0.05). Numbers indicate the number of participants plotted. Asterisks indicate significant pairwise differences by the Mann-Whitney test. GES, gene expression score.
Gene signature associates with an antibody effector function in a human vaccine trial
Immune responses correlating with this signature can provide additional insights into mechanisms that could be harnessed to improve vaccine design. We previously showed in the NHP studies that the protective gene signature that was enriched in uninfected monkeys after Ad26/gp140 vaccination was also associated with higher magnitude of ADCP bib16. In the RV144 human trial a number of immunological parameters were previously measured as part of the immune-correlates analysis, but not ADCP. The RV306 immunogenicity trial that employed a similar prime-boost RV144 vaccine regimen with additional late boosts provided us with a unique opportunity to test if the gene signature was associated with ADCP bib40. We generated transcriptome-wide gene expression data from peripheral blood 2 weeks after the RV144 vaccine regimen (prior to the additional boosts) and assessed for enrichment of the gene signature with the magnitude of ADCP measured at the same time point in 24 participants. The gene signature with 118 enriched genes was significantly associated with higher magnitude of ADCP (NES=3.0, p<0.001) (Figure 3A, Supplementary file 1b). Using the same geneset, 93 genes were found to be enriched in a subset of overlapping participants (N=21), where samples were collected 3 days after the RV144 immunizations (NES=2.5, p<0.001) (Figure 3A, Supplementary file 1b). The model built using ADCP GES from day 3 was able to predict ADCP responses measured 2 weeks after the last vaccination with an accuracy of 0.71. The receiver operator characteristic (ROC) curve illustrates the discriminating ability of the classifier from the day 3 training data set (AUC=0.8, 95% confidence interval [CI]: 0.6–0.99, p=0.01) and the week 2 testing data set (AUC=0.73, 95% CI: 0.5–0.95, p=0.03) to predict ADCP responses (Figure 3B). To evaluate these findings in the context of an efficacy trial, a GES from the list of enriched genes associating with ADCP from both time points was computed in the RV144 study. ADCP GES from both time points correlated strongly with the protective RV144 GES (Rho=0.74, p=2.2e−16, Rho=0.75, p=2.2e−16) (Figure 3C–D). Given the strong correlation in RV144 for the enriched genes from both time points with infection status, we investigated the overlapping 82 genes from day 3 and week 2 time points in a prediction analysis (Figure 4A–B). In addition to being able to successfully predict ADCP magnitude, the genes also show a very clear distinction between the high versus low ADCP groups at both time points (Figure 4C, Supplementary file 1b). To gain understanding of the potential role of the 82 genes, we used GeneMANIA to explore the gene function of the 82 overlapping genes based on physical interaction, co-expression, co-localization, and shared pathways. There were 41 genes that belonged to specific top pathways including the immune system, innate immune system, signaling by interleukins, hallmark inflammatory response, hallmark TNFA signaling via NFKB, cell-cell communication, interleukin-10 signaling, signal regulatory protein family interactions, and pentose phosphate pathway (Figure 4D, Supplementary file 1c). A focused search for gene ontology (GO) terms identified four genes with phagocytosis pathway membership (TYROBP, SIRPA, SIRPB1, and RAB20) (Supplementary file 1d).
# Reading in GSEA result folders
v5Bwk26ADCP <- read.table(file = "data/v5B_ADCP_wk26_method_2_GT.Gsea.1592331997827/GSE29618_BCELL_VS_MONOCYTE_DAY7_FLU_VACCINE_DN.xls", sep = "\t", header = T)
v6wk26ADCP <- read.table(file = "data/v6_ADCP_wk26_method_2_GT.Gsea.1592331997828/GSE29618_BCELL_VS_MONOCYTE_DAY7_FLU_VACCINE_DN.xls", sep = "\t", header = T)
# Reading in GSEA run statistics
gsea_results <- read_xlsx("data/Updated_core_enrichment.xlsx", sheet = 2)
# Setting plot labels
x_lab = paste("\U2190","ADCP High Rank in Ordered Dataset ADCP Low", "\U2192")
y_lab = "Enrichment Score (ES)"
### Updated Enrichment Plots (combined Day 3 + Week 2)
# Creating legends for Day 3 (v5B)
nes_v5Bwk26ADCP = signif(gsea_results %>%
filter(analysis == "v5B_ADCP_wk26_GT") %>%
dplyr::select(NES), digits=2)
pval_v5Bwk26ADCP = ifelse(round(gsea_results %>%
filter(analysis == "v5B_ADCP_wk26_GT") %>%
dplyr::select(NOM.p.val), digits=3) == 0, 0.001,
round(gsea_results %>%
filter(analysis == "v5B_ADCP_wk26_GT") %>%
dplyr::select(NOM.p.val), digits=3))
name_v5Bwk26ADCP = "Day 3"
legend_v5Bwk26ADCP = paste(name_v5Bwk26ADCP, " NES = ", nes_v5Bwk26ADCP, ", p < ", pval_v5Bwk26ADCP, sep="")
max_v5Bwk26ADCP<- max(v5Bwk26ADCP$RANK.IN.GENE.LIST)
# Creating legends for Week 2 (v6)
nes_v6wk26ADCP = signif(gsea_results %>%
filter(analysis == "v6_ADCP_wk26_GT") %>%
dplyr::select(NES), digits=2)
pval_v6wk26ADCP = ifelse(round(gsea_results %>%
filter(analysis == "v6_ADCP_wk26_GT") %>%
dplyr::select(NOM.p.val), digits=3) == 0, 0.001,
round(gsea_results %>%
filter(analysis == "v6_ADCP_wk26_GT") %>%
dplyr::select(NOM.p.val), digits=3))
name_v6wk26ADCP = "Week 2"
legend_v6wk26ADCP = paste(name_v6wk26ADCP, " NES = ", nes_v6wk26ADCP, ", p < ", pval_v6wk26ADCP, sep="")
max_v6wk26ADCP<- max(v6wk26ADCP$RANK.IN.GENE.LIST)
# Plotting ES v/s Rank
plotmax <- ifelse(max_v5Bwk26ADCP > max_v6wk26ADCP, max_v5Bwk26ADCP, max_v6wk26ADCP)
tplot1 <- ggplot(data = v6wk26ADCP, aes(x = RANK.IN.GENE.LIST, y = RUNNING.ES)) +
geom_line(aes(color ="#2844c9"), size=1) +
geom_line(data = v5Bwk26ADCP, mapping = aes(x = RANK.IN.GENE.LIST, y = RUNNING.ES, color="red"), size=1) +
labs(x = x_lab, y = y_lab, color = "Legend\n") +
scale_color_manual(labels=c(legend_v6wk26ADCP, legend_v5Bwk26ADCP), values=c("#2844c9", "red")) +
theme_bw()
tplot3 <- tplot1 + theme(panel.grid.major = element_blank(), panel.grid.minor = element_blank(),
panel.background = element_blank()) +
theme(axis.title.y = element_text(colour="black",size=16, family="Arial"),
axis.title.x = element_text(colour="black",size=16, family="Arial"),
axis.line = element_line(color="black"),
axis.text.x=element_text(color="black",size="14",family="Arial"),
axis.text.y=element_text(color="black",size="14", family="Arial"),
panel.border = element_blank(),
panel.background = element_blank()) +
geom_hline(yintercept=0,color="black") +
theme(legend.position ="bottom", legend.title=element_blank(),
plot.margin = unit(c(1,1,1,1), "cm"),
legend.text=element_text(color="black",size="14", family="Arial")) +
xlim(0, plotmax) + ylim(-0.3, 0.7) +
theme(legend.justification = c(1, 1), legend.position = c(1, 1), legend.box.margin=margin(rep(2, 4)))
tplot3Strong relationship between functional ADCP responses in a human vaccine trial and the protective RV144 signature.
The geneset that associated with protection in an efficacy study was also enriched with higher magnitude of ADCP measured 2 weeks after vaccination in an immunogenicity trial that employed the RV144 vaccine regimen. NES from RNA-seq data at time points (A) 2 weeks (118 enriched genes) (N=24) and 3 days (93 enriched genes) (N=21) post the RV144 vaccine regimen in the RV306 trial are indicated.
load("Data/RV306 ADCP GES.RData")
mydata_rv306_v5b_ADCP_wk26$y = ifelse(mydata_rv306_v5b_ADCP_wk26$adcpGT_wk26_vac_cat_updated == "Low",1,0)
mydata_rv306_v6_ADCP_wk26$y = ifelse(mydata_rv306_v6_ADCP_wk26$adcpGT_wk26_vac_cat_updated == "Low",1,0)
mylogit=glm(y ~trans_93, data=mydata_rv306_v5b_ADCP_wk26,family = binomial(link = "logit"))
prob=predict(mylogit,type=c("response"),newdata = mydata_rv306_v5b_ADCP_wk26)
pred=prediction(prob,mydata_rv306_v5b_ADCP_wk26$y)
perf=performance(pred,"tpr","fpr")
par(mar=c(5.1, 5.1, 5.1, 5.1), bty = 'l',family = "sans")
plot(perf, col="red", xlab="1-Specificity",
ylab="Sensitivity",font.axis=2,lwd=2,main =" " )
abline(0,1,lwd=2)
auc=performance(pred,"auc")
auc=round(unlist(slot(auc,"y.values")),2)
y_obs=mydata_rv306_v5b_ADCP_wk26$y
probpred=predict(mylogit, mydata_rv306_v5b_ADCP_wk26, type="response")
p=roc.area(y_obs,probpred)$p.value
ci=ci.auc(mydata_rv306_v5b_ADCP_wk26$y,mydata_rv306_v5b_ADCP_wk26$trans_93)
legend(0.5, 0.4, c(paste("Training (Day 3)"), paste("AUC = ",round(auc,2))), cex = 0.9,text.col = "red", bty = "n")
### v6 #####
prob <- predict(mylogit, mydata_rv306_v6_ADCP_wk26, type="response")
pred=prediction(prob,mydata_rv306_v6_ADCP_wk26$y)
perf=performance(pred,"tpr","fpr")
par(new=TRUE)
plot(perf, col="blue", xlab="",
ylab="",lwd=2)
auc=performance(pred,"auc")
auc=round(unlist(slot(auc,"y.values")),3)
y_obs=mydata_rv306_v6_ADCP_wk26$y
probpred=predict(mylogit, mydata_rv306_v6_ADCP_wk26, type="response")
p=roc.area(y_obs,probpred)$p.value
ci=ci.auc(mydata_rv306_v6_ADCP_wk26$y,mydata_rv306_v6_ADCP_wk26$trans_93)
legend(0.5, 0.2, c(paste("Test (Week 2)"), paste("AUC = ",round(auc,2))), cex = 0.9,text.col = "blue", bty = "n")The model built using ADCP GES from day 3 was able to predict ADCP responses measured 2 weeks after the last vaccination with an accuracy of 0.71. The ROC curve illustrates the discriminating ability of the classifier from the day 3 training data set (AUC=0.8, 95% CI: 0.6–0.99, p=0.01) and the week 2 testing data set (AUC=0.73, 95% CI: 0.5–0.95, p=0.03) to predict ADCP responses.
load("data/mydata_rv144_GES_cor.RData")
trans63=mydata_rv144_GES_cor$trans_63
trans91=mydata_rv144_GES_cor$trans_91
trans115=mydata_rv144_GES_cor$trans_115
##### CORRELATION & PLOT ##########
### TRANS91 ####
myplot=as.data.frame(cbind(trans63,trans91))
p91 <- ggplot(myplot, aes(x = trans63, y = trans91)) +
geom_point()+
xlab("GES Infection") +
ylab("GES ADCP Day 3") +
theme_bw() +
theme(text=element_text(family="Arial"),
axis.text = element_text(color = "black", size = 12),
axis.title = element_text(size = 14),
panel.border = element_blank(), panel.grid.major = element_blank(),
panel.grid.minor = element_blank(), axis.line = element_line(colour = "black")) +
stat_smooth(formula = y ~ x, method = "lm",
col = "#C42126",
se = FALSE,
size = 1)
### TRANS115 ####
myplot=as.data.frame(cbind(trans63,trans115))
p115 <- ggplot(myplot, aes(x = trans63, y = trans115)) +
geom_point()+
xlab("GES Infection") +
ylab("GES ADCP Week 2") +
theme_bw() +
theme(text=element_text(family="Arial"),
axis.text = element_text(color = "black", size = 12),
axis.title = element_text(size = 14),
panel.border = element_blank(), panel.grid.major = element_blank(),
panel.grid.minor = element_blank(), axis.line = element_line(colour = "black")) +
stat_smooth(formula = y ~ x,method = "lm",
col = "#C42126",
se = FALSE,
size = 1)
p115 + annotate("text", x = 0.7, y = 1.4, label = "Rho = 0.74 p = 2.2e-16",col = "black",family = "Arial", size = 4.5)GES computed from the enriched genes associating with ADCP correlated strongly with the protective GES in the RV144 study (N=170) at time points 2 weeks (115 enriched genes) post the RV144 vaccine regimen. ADCP, antibody-dependent cellular phagocytosis; CI, confidence interval; GES, gene expression score; NES, normalized enrichment score.
p91 + annotate("text", x = 0.7, y = 1.3, label = "Rho = 0.75 p = 2.2e-16",col="black",family="Arial", size = 4.5)
GES computed from the enriched genes associating with ADCP correlated strongly with the protective GES in the RV144 study (N=170) at time points 3 days (91 enriched genes) post the RV144 vaccine regimen. ADCP, antibody-dependent cellular phagocytosis; CI, confidence interval; GES, gene expression score; NES, normalized enrichment score.
enriched_genes = read_xlsx("data/Gene_lists.xlsx", sheet = 1)
names(enriched_genes)[c(5,6)] = c("Day 3", "Week 2")
enriched_gene_lists = as.list(enriched_genes)
# Removing NA from Day 3 list, caused due to difference in number of row
enriched_gene_lists$`Day 3` = na.omit(enriched_gene_lists$`Day 3`)
# Plotting a Venn diagram with required colors
ggvenn(enriched_gene_lists, c("Day 3","Week 2"), show_percentage=FALSE,
text_size = 6, fill_color = c("red",rgb(10,100,200,max=255)), fill_alpha = 0.85)
Overlapping enriched genes associating with ADCP responses.
There were 82 overlapping genes between the day 3 (N=21) and week 2 (N=24) ADCP enriched genes in the RV306 study.
load("data/RV306 ADCP GES overlap.RData")
mydata_rv306_v5b_ADCP_wk26_overlap82$y = ifelse(mydata_rv306_v5b_ADCP_wk26_overlap82$adcpGT_wk26_vac_cat_updated == "Low",1,0)
mydata_rv306_v6_ADCP_wk26_overlap82$y = ifelse(mydata_rv306_v6_ADCP_wk26_overlap82$adcpGT_wk26_vac_cat_updated == "Low",1,0)
mylogit=glm(y ~trans_82, data=mydata_rv306_v5b_ADCP_wk26_overlap82,family = binomial(link = "logit"))
prob=predict(mylogit,type=c("response"),newdata = mydata_rv306_v5b_ADCP_wk26_overlap82)
pred=prediction(prob,mydata_rv306_v5b_ADCP_wk26_overlap82$y)
perf=performance(pred,"tpr","fpr")
par(mar=c(5.1, 5.1, 5.1, 5.1), bty = 'l',family = "sans")
plot(perf, col="red", xlab="1-Specificity",
ylab="Sensitivity",font.axis=2,lwd=2,main =" " )
abline(0,1,lwd=2)
auc=performance(pred,"auc")
auc=round(unlist(slot(auc,"y.values")),2)
y_obs=mydata_rv306_v5b_ADCP_wk26_overlap82$y
probpred=predict(mylogit, mydata_rv306_v5b_ADCP_wk26_overlap82, type="response")
p=roc.area(y_obs,probpred)$p.value
ci=ci.auc(mydata_rv306_v5b_ADCP_wk26_overlap82$y,mydata_rv306_v5b_ADCP_wk26_overlap82$trans_82)
legend(0.5, 0.4, c(paste("Training (Day 3)"), paste("AUC = ",round(auc,2))), cex = 0.9,text.col = "red", bty = "n")
### v6 #####
prob <- predict(mylogit, mydata_rv306_v6_ADCP_wk26_overlap82, type="response")
pred=prediction(prob,mydata_rv306_v6_ADCP_wk26_overlap82$y)
perf=performance(pred,"tpr","fpr")
par(new=TRUE)
plot(perf, col="blue", xlab="",
ylab="",lwd=2)
auc=performance(pred,"auc")
auc=round(unlist(slot(auc,"y.values")),3)
y_obs=mydata_rv306_v6_ADCP_wk26_overlap82$y
probpred=predict(mylogit, mydata_rv306_v6_ADCP_wk26_overlap82, type="response")
p=roc.area(y_obs,probpred)$p.value
ci=ci.auc(mydata_rv306_v6_ADCP_wk26_overlap82$y,mydata_rv306_v6_ADCP_wk26_overlap82$trans_82)
legend(0.5, 0.2, c(paste("Test (Week 2)"), paste("AUC = ",round(auc,2))), cex = 0.9,text.col = "blue", bty = "n")
The model using GES obtained from the 82 genes was also able to predict ADCP responses measured 2 weeks after vaccination with an accuracy of 0.71. The ROC curve illustrates the discriminating ability of the classifier from the day 3 training data set (AUC=0.81, 95% CI: 0.62–1, p=0.007) and the week 2 testing data set (AUC=0.75, 95% CI: 0.53–0.97, p=0.02) to predict ADCP responses.
# Determining overlapping genes between timepoints and creating heatmap
# Reading in gene expression matrices
v6_data = read.table(file = "data/RV306_v6_forADCP_GSEA.txt", header = T, sep = "\t")
v5B_data = read.table(file = "data/RV306_v5B_forADCP_GSEA.txt", header = T, sep = "\t")
enriched_genes = read_xlsx("data/Gene_lists.xlsx", sheet = 1)
names(enriched_genes)[c(5,6)] = c("Day 3", "Week 2")
enriched_gene_lists = as.list(enriched_genes)
# Removing NA from Day 3 list, caused due to difference in number of row
enriched_gene_lists$`Day 3` = na.omit(enriched_gene_lists$`Day 3`)
overlap_genes = as.data.frame(intersect(enriched_genes$`Day 3`, enriched_genes$`Week 2`))
names(overlap_genes)[1] = "Overlapping_genes"
v6_data = v6_data[-c(1)]
names(v6_data)[1] = "Gene_name"
v6_data = right_join(v6_data, overlap_genes, by = c("Gene_name" = "Overlapping_genes"))
rownames(v6_data) = v6_data$Gene_name
v6_data[1] = NULL
v5B_data = v5B_data[-c(1)]
names(v5B_data)[1] = "Gene_name"
v5B_data = right_join(v5B_data, overlap_genes, by = c("Gene_name" = "Overlapping_genes"))
rownames(v5B_data) = v5B_data$Gene_name
v5B_data[1] = NULL
# Reading in metadata containing sample classification information
metadata = read_xlsx("Data/Gene_lists.xlsx", sheet = 2)
meta_v5B = subset(metadata, Timepoint == "v5B")
meta_v6 = subset(metadata, Timepoint == "v6")
# Subsetting samples only to those with ADCP
v5B_data = v5B_data %>% dplyr::select(meta_v5B$Sample_ID)
v6_data = v6_data %>% dplyr::select(meta_v6$Sample_ID)
combined_set = cbind(v5B_data, v6_data)
# Calculating mean of expression values for each category
combined_set$Day_3_ADCP_High = rowMeans(combined_set[,1:12])
combined_set$Day_3_ADCP_Low = rowMeans(combined_set[,13:21])
combined_set$Week_2_ADCP_High = rowMeans(combined_set[,22:35])
combined_set$Week_2_ADCP_Low = rowMeans(combined_set[,36:45])
average_counts = as.matrix(combined_set[-c(1:45)])
### Using this matrix to create heatmap
# Setting a color scale
orig_col_scale = colorRampPalette(c("white", "orange", "#721427"))(n = 299)
# Created a dataframe categorizing matrix columns by group
# Used for color annotation
color_df = read.table(file = "Data/Color_DF.txt", header = T, sep = "\t", row.names = "Name")
# Assigning colors to categories
annot_colors = list(Timepoint = c("Day 3" = "#12752C", "Week 2" = "#F58142"),
ADCP = c("High" = "#882B8D", "Low" = "#5AC4F7"))
# Plotting the heatmap
p1 = pheatmap(average_counts, color = orig_col_scale, scale = "row",
cluster_rows = T, cluster_cols = F, clustering_method = "complete",
cellheight=8,cellwidth=60,
annotation_col = color_df, annotation_colors = annot_colors,
annotation_legend = T, annotation_names_col = T, border_color = NA,
show_colnames = F, fontsize_row = 7, display_numbers = F,
labels_row = as.expression(lapply(rownames(average_counts),
function(a) bquote(italic(.(a))))))
p2 = ggplotify::as.ggplot(p1) + annotate("text", x = 0.72, y = 0.985, label = "Z-score", fontface = 2, size = 3.5) + theme(panel.background = element_rect(fill = "white", linetype = "blank"))
p2Heatmap showing the hierarchical clustering of gene expression of the 82 genes (day 3 and week 2 after 4th vaccination) when stratified by magnitude of ADCP responses measured 2 weeks after the 4th immunization.
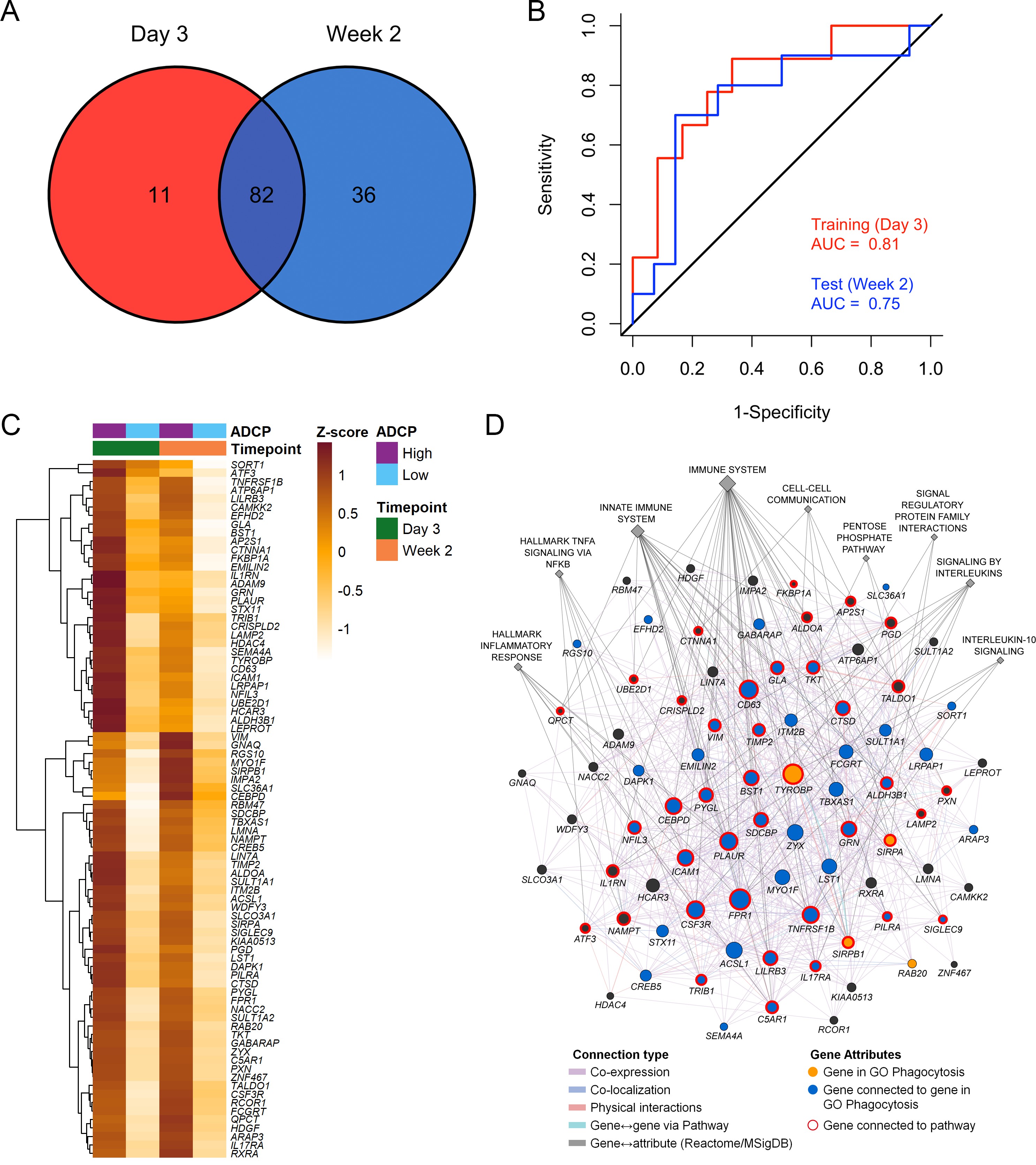
The list of 82 ADCP enriched genes was uploaded in GeneMANIA. Edges represent physical interactions, co-expression, co-localization, and shared pathways. Circles depict the 82 genes, gold circles are the four genes that belong to the gene ontology Phagocytosis pathway, blue circles are genes that are directly connected to them, diamonds indicate related pathways, and the color of the edge indicates the type of connection. ADCP, antibody-dependent cellular phagocytosis; CI, confidence interval; GES, gene expression score; ROC, receiver operator characteristic.
Pathways and genes shared between ADCP and vaccine protection phenotypes
These findings demonstrate a strong link of the geneset with both vaccine protection and ADCP in NHP and human studies. We sought to broaden our understanding of the relationship between the different enriched genes in the geneset and establish some of the top pathways with gene membership from the different studies. Networks and associated pathways from genes that were significantly enriched with either the ADCP or infection phenotypes from the 09–11, 13–19, RV144, and RV306 studies were determined using GeneMANIA. The top pathways were the immune system, innate immune system, H1F1 TF pathway, hypoxia, TNFA signaling via NFKB, cytokine signaling, inflammation response, signaling by interleukins, and IL-10 signaling (Figure 5A). The genes with the most connections were TYROBP, FPR1, CD14, CCR1, TNFRSF1B, CD68, CD63, CEBPD, and LST1. Clustering on the enriched genes to identify highly interconnected regions in the GeneMANIA network showed that TYROBP, FPR1, CD14, TNFRSF1B, CD68, and LST1 were all members of the cluster with the greatest number of genes (Figure 5B). There were no specific enriched genes that were common to all studies (Supplementary file 1b). Pathway enrichment analysis of the 63 genes in the RV144 signature revealed that the top non-redundant enriched clusters with gene membership were myeloid leukocyte activation, lysosome, and cellular response to oxidative stress genes (Figure 5C).
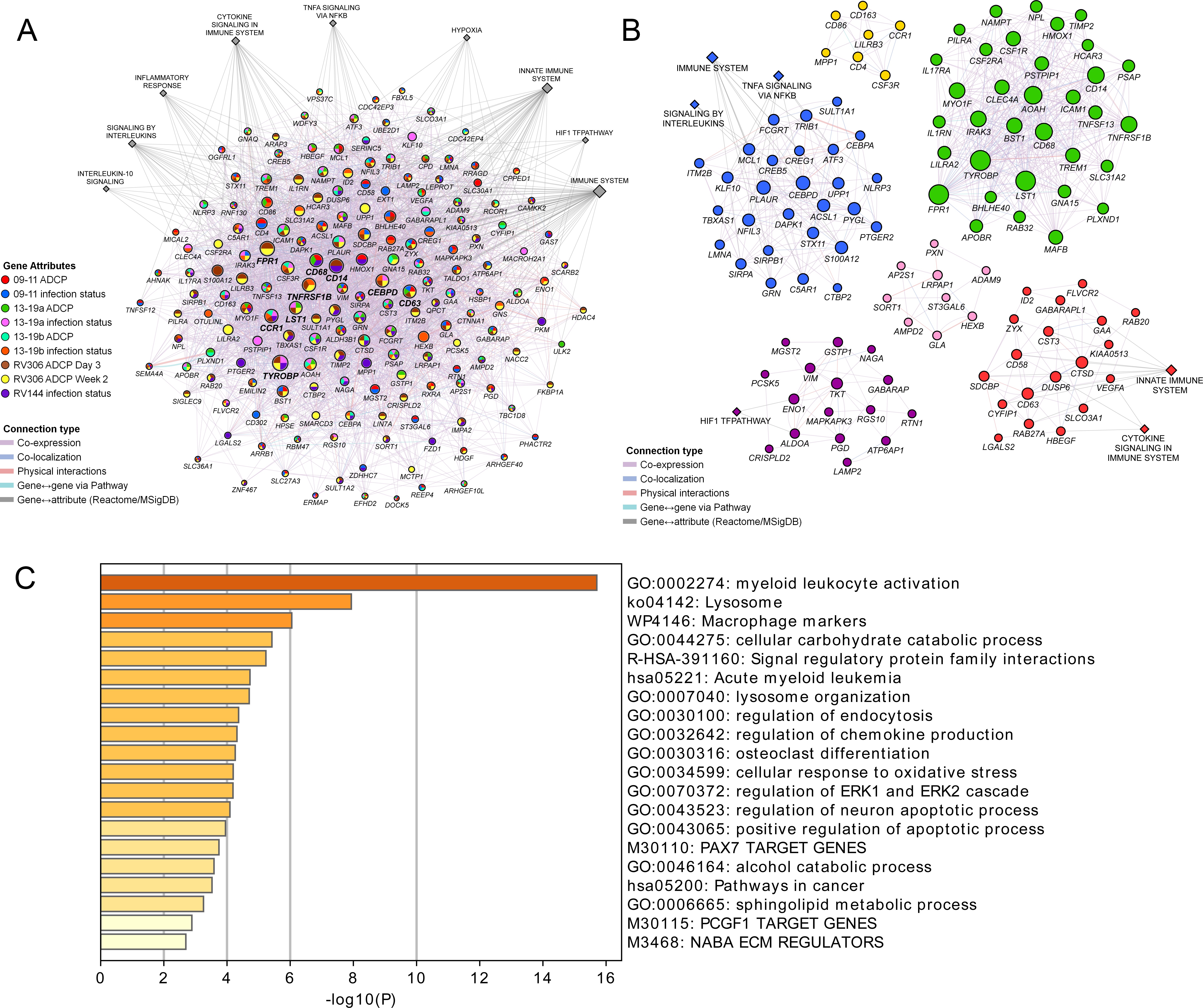
Pathway analyses of the enriched genes in the different vaccine studies.
A meta-analysis of pathways including enriched genes with reduced infection or higher ADCP was performed. (A) Genes that were enriched in at least one of the nine ADCP or infection status analyses (178) were used as input for GeneMANIA in Cytoscape. The connections between the different genes and the top MSigDB and Reactome pathways are shown. Each gene is represented by a circle and size is proportional to the number of connections with other genes or pathways. The color of each node indicates the enrichment status in the different studies. (B) Clustering of the enriched genes from the different studies. The color of each node represents the membership in a cluster and size is proportional to the number of connections with other genes or pathways. (C) Pathway enrichment analysis results of the 63 enriched genes that associated with reduced infection in the RV144 study. ADCP, antibody-dependent cellular phagocytosis.
Cellular origin of the protective genes by single-cell transcriptomics
To dissect the cellular origin of these genes, we performed simultaneous detection of mRNA and cell surface expression from single cells using the cellular indexing of transcriptomes and epitopes by sequencing (CITE-seq) technology in a subset of the vaccinated RV306 participants (Figure 6A). This technology allows simultaneous detection of cell surface markers and mRNA gene expression from the same single cells. Our analyses revealed that a majority of the genes in the RV144 signature were expressed in cells of the myeloid lineage, with monocyte subsets having the highest average gene expression (Figure 6B). A subset of 32 genes were also significantly associated with decreased risk of acquisition in a univariate analysis (odds ratio [OR]<1.0, p<0.05, q<0.1) (Figure 6C). A GES of the 32 significant genes is also associated with decreased risk of acquisition, increased VE, and was able to predict infection status in RV144 (Figure 6—figure supplement 1A-D). A stepwise logistic regression analysis identified specific genes (SEMA4A, SLC36A1, SERINC5, IL17RA, CTSD, CD68, and GAA) to have independent associations with reduced risk of acquisition and was mainly expressed in the monocyte compartment (Figure 6D). CD14+ monocytes also had the greatest number of DEGs that were associated with ADCP, which was not dependent on the frequency of the cell subset (Figure 6E, Figure 6—figure supplement 2).
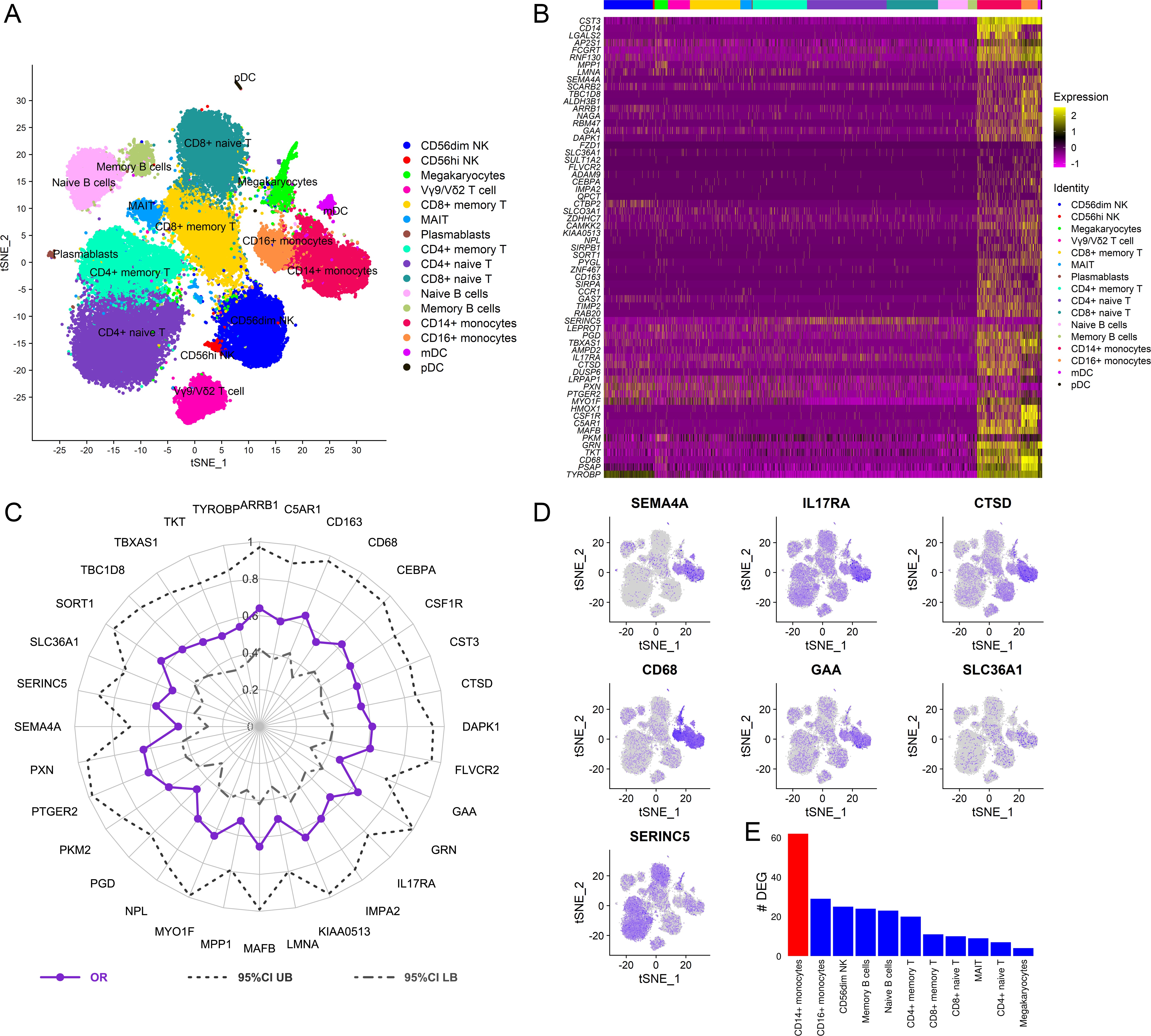
Cellular origin of the RV144 signature.
Single-cell CITE-seq in vaccinated participants (N=12) who received the RV144 vaccine regimen (day 3 after last vaccination) identified expression of the genes in the signature in cells from the myeloid lineage. (A) Clustering based on cell surface expression of CITE-seq data. (B) Heatmap of the mRNA expression of the 63 genes from the RV144 signature from single cells. Columns represent single cells from different protein cell subsets and rows the mRNA gene expression. (C) Radar plot showing significant genes in the signature that associated with decreased risk of infection in RV144 (p<0.05, q<0.1) (N=170). (D) Feature plots of the expression of the most protective genes show that SEMA4A, IL17RA, CTSD, CD68, and GAA were mainly expressed in monocytes. (E) CD14+ monocytes had the highest number of differentially expressed genes (DEGs) when comparing high versus low ADCP (2 weeks after vaccination) from single-cell CITE-seq vaccinated participants who received the RV144 vaccine regimen (day 3 after last vaccination). ADCP, antibody-dependent cellular phagocytosis.
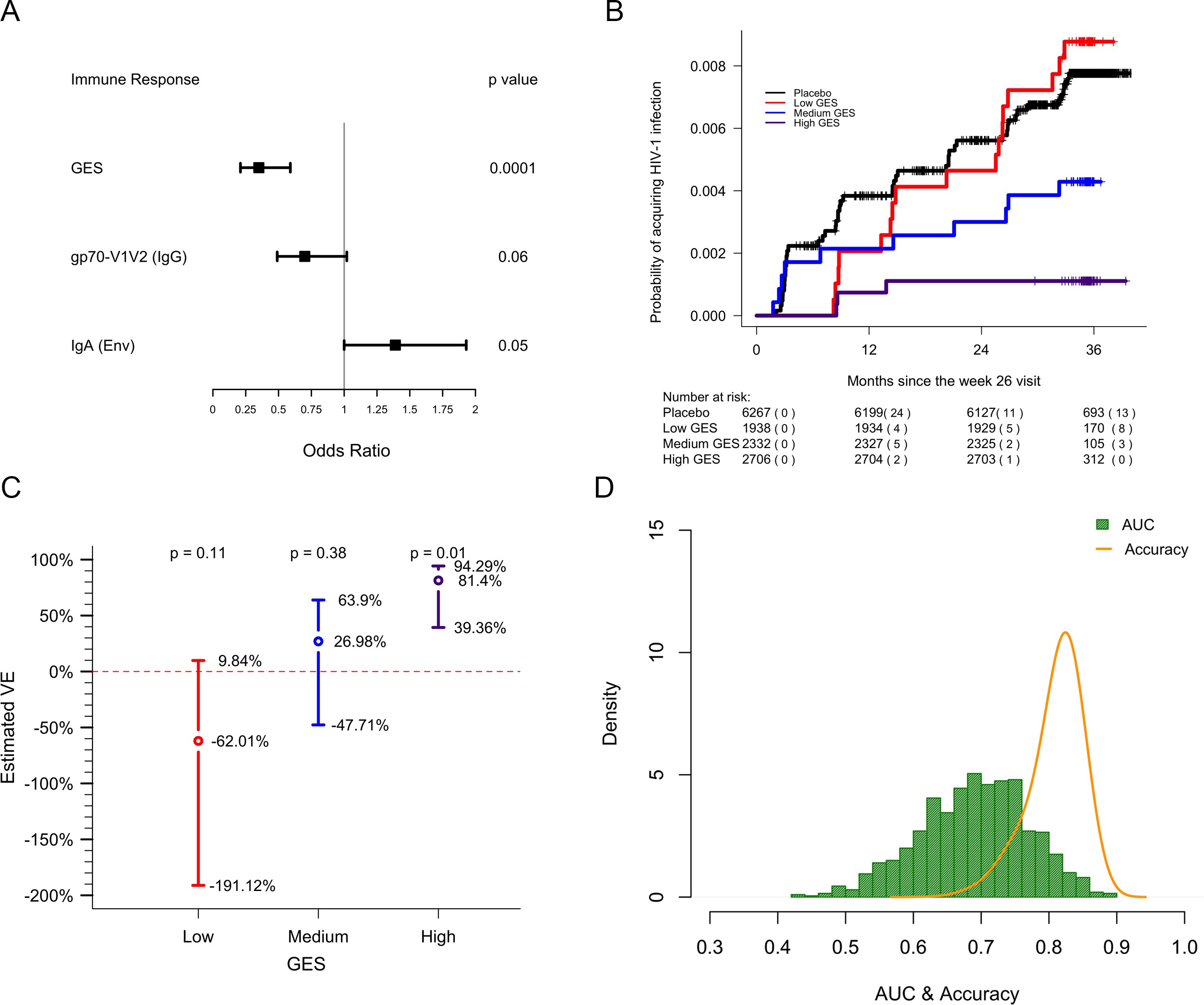
GES of the most significant genes is a correlate of reduced risk of infection in RV144.
A GES of the 32 enriched genes that were also significantly associated with decreased risk of acquisition in a univariate analysis in the RV144 study was examined as a continuous variable (N=170). (A) GES is associated with lower odds of HIV acquisition compared to the other two primary correlates of risk. Variables were measured at week 26, 2 weeks post last vaccination. For each variable, the OR is reported per 1-SD increase. Transcriptome data was available only in a subset of the 246 donors. (B) Probability of acquiring HIV-1 is lower in individuals with higher GES. (C) Vaccine efficacy is increased significantly in individuals with high GES. (D) Distribution of AUC and accuracy plotted after repeating the process 1000 times showed that GES could predict HIV-1 infection with AUC of 0.69±0.08 and with accuracy of 0.81±0.04. GES, gene expression score; OR, odds ratio.
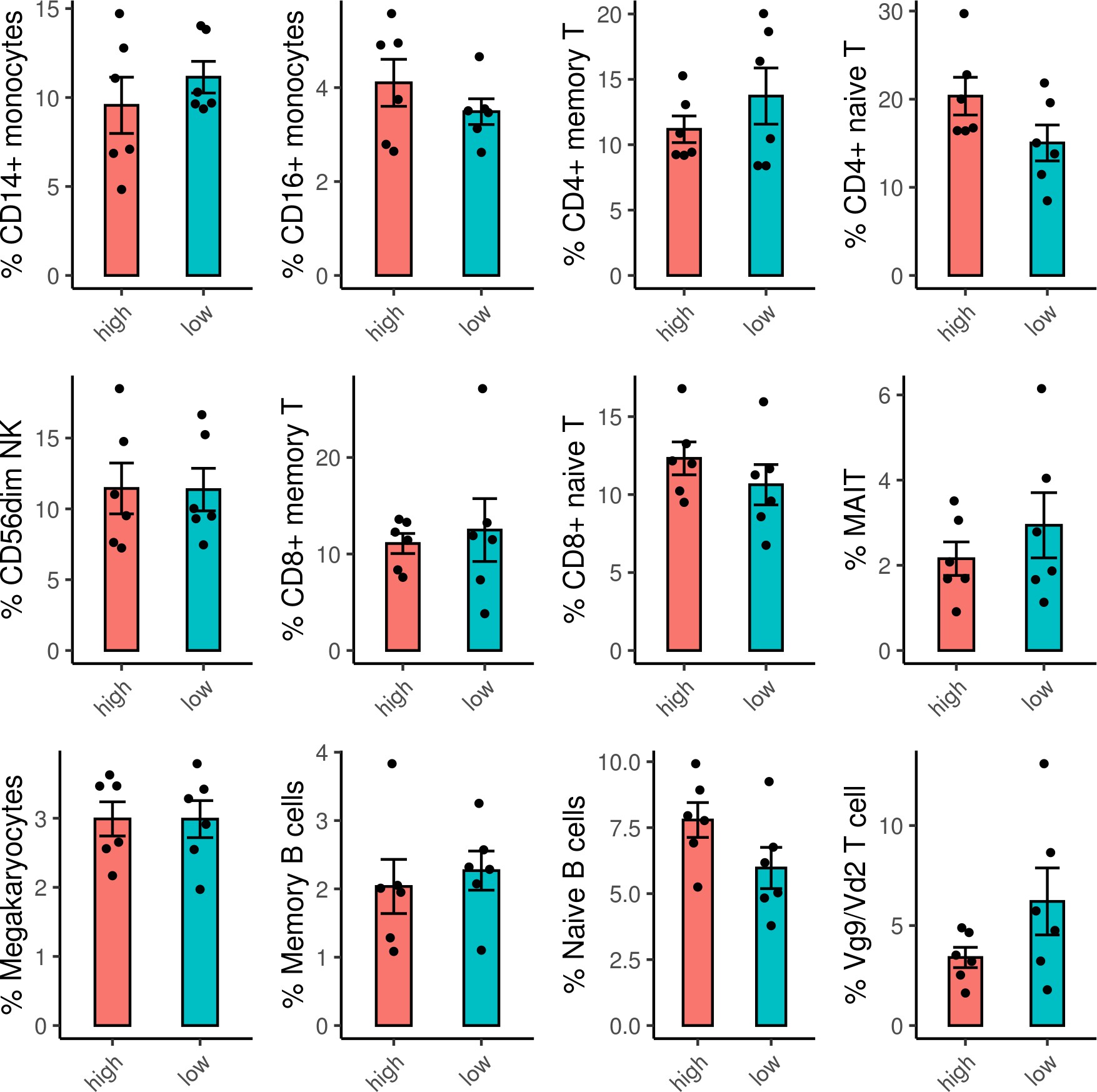
Frequencies of cell subsets do not differ between ADCP high and low samples.
Frequencies of each cell subset were calculated for each sample. For the cell subsets with average frequencies >1 % of the sample, there were no significant differences between the frequencies of the cell subsets in the ADCP high versus low samples. ADCP, antibody-dependent cellular phagocytosis.
Discussion
Though an effective vaccine has been a challenge for the HIV field, we see a glimpse of optimism in partially protective NHP and human studies bib8bib7bib9bib43bib56bib55. These studies provide a unique opportunity to identify correlates of reduced risk that could help inform protective signals and enable the design of enhanced vaccine strategies. Targeted and unbiased approaches have implicated non-neutralizing antibodies as the major correlate of reduced risk of HIV infection bib8bib7bib9bib24bib56bib55. We previously showed that a transcriptomic signature first identified in sorted B cells at time points prior to challenge was a correlate of protection in two NHP studies after administration of the Ad26/gp140 vaccine. This signature is also associated with the increased magnitude of ADCP in the vaccinated monkeys bib16. Additionally, we identified this signature in bulk PBMC from other studies that used the ALVAC/protein regimen, suggesting that the gene signature might be an indicator of effective vaccination. In this report, we further investigated this gene signature to answer the following questions, including: (1) can the gene signature’s association with protection be substantiated in additional human efficacy trials, (2) does it associate with ADCP in human trials, and (3) what is the cellular origin of the signature at the single-cell level?
The gene signature was previously associated with HIV vaccine protection in a number of studies with partial protection bib16. We hypothesized that if this geneset was a true marker of HIV vaccine protection, it would not be enriched in a failed vaccine trial. HVTN 505 is a DNA based vaccine which, despite not showing overall efficacy in a Phase 2b trial, demonstrated both cellular and antibody effector mediated protection in specific subgroups of individuals in follow-up studies bib18bib25bib34. We performed transcriptomics on sorted cell subsets from HVTN 505 vaccinated individuals and did not observe enrichment of the gene signature, further strengthening our notion that the geneset could be a proxy for vaccine protection. Given that this signature is derived by comparing infected versus uninfected vaccinated groups, this analysis was only tested in studies with partial protection, and not in vaccine regimens where all recipients were infected.
Next, we developed a method to assess this gene signature compared to other correlates of risk in the human RV144 study. This method employs an analytical method using a GES which is computational score generated from the average expression of all genes enriched in the signature and associating with a phenotype. This method was tested across different NHP studies and RV144 and showed consistent association with reduced risk of infection based on the study-specific GES. The composite GES computed from RV144 consisting of the standardized expression of 63 genes had the strongest association with decreased risk of infection and increased vaccine efficacy. The RV144 GES was also able to accurately predict infection status in the study. This study shows that the GES composite score provides a robust analytical measurement to explore the effect of genes as a continuous variable in immune-correlates analyses, and that it could be applied to other ongoing efficacy studies. Further, the analysis of RV144 breakthrough infections was consistent with GES being lower in the vaccinated infected participants compared to placebos and hence protective. These observations, albeit only significant in the group infected with single founder viruses, strengthen the premise of the RV144 GES being a correlate of reduced risk of infection.
We previously showed in NHP challenge studies that the gene signature correlated with an increased magnitude of functional antibody responses bib16. Although this geneset is associated with ADCP in NHP, the same analyses were previously not possible in the human RV144 study since this immune response was not reported bib24. ADCP has since been implicated with vaccine protection in a number of NHP challenge studies bib2bib8bib7bib9bib11bib34. It is reported that ADCP could be involved in most studies that previously showed antibody-dependent correlates of protection against viruses bib54. To investigate the effect of the gene signature on the magnitude of ADCP, we performed transcriptomics in samples from a human trial (RV306) that employed the same RV144 regimen. At both day 3 and 2 weeks after the 4th vaccine corresponding to the last RV144 vaccine dose, this signature was associated with an increased magnitude of ADCP responses. A strong correlation was also observed between GES from the ADCP enriched genes and the vaccine protection genes in RV144. The ADCP GES at both day 3 and week 2 after the last vaccination was able to predict ADCP magnitude at peak immunity. Similarly, a GES of the 82 overlapping genes between the two time points was also able to predict ADCP magnitude. This finding would suggest that measuring gene expression 3 days after vaccination in preclinical and clinical trials may be used as a tool for titrating effective responses. Although the 82 genes did not have membership in a previously described Fc-gamma receptor signaling pathway, a GO query identified SIRPA, SIRPB1, RAB20, and TYROBP in the phagocytosis GO term bib51 (http://amigo.geneontology.org/amigo/term/GO:0006909#display-lineage-tab). These four genes were also connected to an additional 44 genes from the total 178 genes enriched in at least one of our GSEA analyses, supporting a possible role in phagocytosis (Supplementary file 1d). SIRPA and SIRPB are signal regulatory proteins that are expressed on myeloid cells, and the former is known to bind to CD47 to regulate migration and phagocytosis bib6. RAB20 is a member of the Rab GTPase family and is involved in phagosome maturation bib46. Finally, TYROBP had the maximum connections in a network of these genes, was present in the largest cluster, and was related to other highly connected genes expressed in effector cells such as monocytes or neutrophils. TYROBP (DAP12) is a cytosolic adaptor that associates with triggering receptors expressed on myeloid cells (TREMs) to promote phagocytosis bib38. Genes such as TNFSF13 and BHLHE40 that were previously identified as protective against SIV/SHIV acquisition in the NHP model were also present in the same cluster, supporting a similar function bib16. Taken together, these findings provide evidence supporting the antibody-mediated effector function as a potential mechanistic basis of this protective gene signature.
The enriched genes from ADCP and infection risk in multiple studies of both NHP and human were involved in overlapping functions related to leukocyte activation, lysosomal degradation, and immune stimulation by cytokines. The 63 genes from the RV144 signature had the highest membership in the myeloid leukocyte activation pathway, perhaps alluding to the cellular origin of this signature. The specific genes in the geneset that associated with the greatest odds of reduced risk of infection including SEMA4A, CTSD, CD68, and GAA were all members of this pathway, but not TNFSF13 (APRIL) which was the most protective gene in the NHP studies. Although the geneset of interest was first seen in sorted B cells from vaccinated NHP, it was subsequently identified in transcriptomic data from PBMC in the RV144 study bib16. While samples were exhausted from the RV144 primary data set, the RV306 clinical trial that employed the same ALVAC/protein vaccine regimen gave us a unique chance to explore the cellular origin of the RV144 signature using single-cell transcriptomics. Single-cell surface expression data revealed that the majority of genes were expressed in monocytes, which was not surprising given the fact that this geneset was originally defined as genes downregulated in B cells compared to monocytes after influenza vaccination bib33. While our initial study found this signature in sorted B cells from the NHP challenge studies, single-cell data provides further insight that monocytes could be the cellular origin of these genes in the RV144 study. Although monocytes were classified as mononuclear phagocytes almost 50 years ago, assays designed to specifically measure monocyte ADCP were not widely used in the context of vaccination until a few years ago bib57. While monocytes have been implicated in vaccine-induced protection in preclinical vaccine trials of SIV challenge, our findings in human trials at the single-cell level provide greater impetus to explore the role of other non-lymphoid cell populations on HIV-1 VE bib21bib56. Though we think that monocytes are important in the vaccine responses observed in RV144, it would be remiss not to mention that the effect of granulocytes (including neutrophils) in response to vaccination is missed when transcriptomics is performed in PBMC compared to blood. Regardless of the cellular origin, we think this set of 200 genes with a coordinated expression may not be specific to a cell type, but might mark a certain biological state, such as response to a cytokine, and can be identified even in PBMC and blood samples. Other than the phagocytic cell, antibody and Fc receptor diversity can also influence ADCP mediated immune responses to viral pathogens and are elements that warrant further study and may potentially be manipulated to improve VE bib14bib20bib54.
Our data demonstrate the potential to discover novel protective correlates using an approach that mines transcriptomic data in multiple preclinical and clinical trials. Unbiased transcriptome-wide analyses are able to identify biological perturbations that associate with vaccine protection even when differences are small, but credibility can only be strengthened by replicating findings across multiple studies. Gene signatures that associate not only with vaccine protection but with specific immune responses can be a prospective tool to evaluate vaccine effectiveness even prior to challenge or infection. Developing analytical tools that can interface with phenotypes such as vaccine protection across human and preclinical studies can allow for more systematic meta-analyses of data emerging from the ongoing, non-efficacious, or halted HIV vaccine clinical trials bib22bib36bib37. We propose that assessment of such gene signatures with immune responses in human immunogenicity trials could provide orthogonal insight for down-selection of vaccine candidates. Identifying overlapping immune correlates could be pivotal to making discoveries that may allow for licensure and subsequent bridging studies of an effective HIV vaccine.
Materials and methods
Study design
The aim of the study was post hoc analyses of a protective gene expression signature identified previously in five SIV/HIV vaccine studies with efficacy and immune response data bib16. To enable interpretation of this gene signature, bulk RNA-seq, scRNA-seq, and functional data were generated in clinical samples from the RV306 and HVTN 505 human trials. The RV306 vaccine trial was conducted in Thailand and all participants received the primary RV144 ALVAC/gp120 vaccine series, with additional late boosts assigned to specific groups bib40. Bulk RNA-seq was performed in 24 participants 2 weeks after the RV144 vaccine regimen (week 26). Additionally, RNA-seq was also performed 3 days after the same primary endpoint. The HVTN 505 trial used a DNA/rAd5 vaccine regimen to test safety and efficacy in a US population bib23. PBMC collected 1 month after the final immunization (month 7) was available from 47 vaccines in the HVTN 505 study for RNA-seq bib23. The infection status of the vaccinees (22 cases and 25 controls) was categorized based on infection status between months 7 and 24. Microarray transcriptome data from PBMC and immune response data for 170 vaccinated individuals from the RV144 study at time point 2 weeks post last vaccination was used for correlates analyses bib19bib24. All studies were approved by the participating local and international institution review boards. Informed consent was obtained from all participants in the different trials included in this study bib23bib40.
Bulk transcriptomics
RNA was extracted from sorted B cells (Aqua live/dead−CD20+CD3−) and monocytes (Aqua live/dead−CD20−CD3−CD56−HLA-DR+CD14+) from PBMC of HVTN 505 vaccinees using RNAzolRT (MRC Inc) as per recommendations from the manufacturer. For the preparation of mRNA libraries, polyadenylated transcripts were purified on oligo-dT magnetic beads, fragmented, reverse transcribed using random hexamers, and incorporated into barcoded cDNA libraries based on the Illumina TruSeq platform. Next, libraries were validated by electrophoresis, quantified, pooled, and clustered on Illumina TruSeq v2 flow cells. Clustered flow cells were sequenced on an Illumina HiSeq (2000/4000) using 2×75 base paired-end runs. Total RNA from RV306 participants was extracted from whole blood collected in PAXgene Blood RNA tubes using associated RNA extraction (both QIAGEN; Germantown, MD) and GlobinClear purification kits (Thermo Fisher Scientific; Waltham, MA) as per the manufacturer’s suggestions. RNA-seq was performed using the SMART-Seq technology bib39bib42. Briefly, cDNA was generated from 10 ng of RNA using the SMART-Seq v4 UltraLow Input RNA Prep Kit (Takara Bio Inc) as per the manufacturer’s suggestions, with control RNA spiked-in (Thermo Fisher Scientific). Sequencing libraries were generated using the Nextera XT DNA Sample Prep Kit (Illumina, San Diego, CA). Concentration of each sample in the pooled libraries was determined using the paired-end 300-cycle MiSeq Reagent Nano Kit v2 (2×150 bp) on a MiSeq instrument (both Illumina). Next-generation sequencing was performed on a final adjusted library pool using the paired-end 300-cycle NovaSeq 6000 S2 XP Reagent Kit (2×150 bp) on a NovaSeq instrument (both Illumina) as per the manufacturer’s instructions. Fastp v0.19.7 and Trimmomatic v0.33 with default parameters were used to trim low-quality bases from both ends of each read bib10bib13. Trimmed reads were aligned to the human genome (GRCh38 build 88–92) using HISAT2 v2.1.0 or the STAR aligner (v2.4.2a) and HTSeq (v0.6.1–0.9.1) was used for counting bib15bib26bib3. Trimmed mean of M-values normalization method, as implemented in the R package edgeR, was used for normalization bib44.
Single-cell transcriptomics
Simultaneous evaluation of mRNA and cell surface expression from single cells was performed using feature barcoding (FB) technology from 10× Genomics, based on the CITE-seq technology bib47. Cell hashing (HTO) was used in conjunction with the 10× Genomics 5’V(D)J Feature Barcoding Kit to generate single-cell mRNA gene expression (GEX) and antibody-derived tag (ADT) libraries bib47bib48. Briefly, PBMC from 12 samples were hashed using TotalSeq-C anti-human Hashtag antibodies and combined into two batches. In each batch, surface proteins were stained with a cocktail of 53 TotalSeq-C antibodies (BioLegend). Antibody concentrations were either predetermined by titration bib27 or used at a default concentration. 50,000 cells from each batch were loaded onto each of four wells of a Chromium chip, and GEX and ADT (HTO and FB) libraries were constructed following the manufacturer’s protocol. Libraries were pooled and quantitated using a MiSeq Nano v2 reagent cartridge. Final libraries were sequenced on the NovaSeq 6000, S4 reagent cartridge (2×100 bp) (Illumina).
CITE-seq data analyses
FASTQ files were demultiplexed with bcl2fastq v2.20 (Illumina). Alignment and counting were performed using Cell Ranger v3.1.0 (10× Genomics) and the human reference files provided by 10× Genomics (human genome GRCh38 and Ensembl annotation v93). The average number of genes per cell was 1453 and the average number of unique molecular identifiers was 4248. The mean read depth per cell was approximately 65,000–84,000. The minimum fraction of reads mapped to the genome was 88% and sequencing saturation was above 85% for all lanes, with an average of 88%. The computational analysis of ADT data was performed using the Seurat v3.1 package bib49. HTO expression matrices were CLR (Centered Log-Ratio) normalized and demultiplexed using MULTIseqDemux. The FB matrices from the Seurat objects were split into cell-positive and negative droplet matrices using the HTO demultiplexing results, and were used for DSB (Denoised and Scaled by Background) normalization bib27 (https://cran.r-project.org/web/packages/dsb/index.html). Only cells with <10% mitochondrial genes were retained, and cells were assigned to specific donors using the HTO demultiplexing results. A total of 53,777 single cells remained after the quality control process. The gene expression matrices for all samples were normalized and integrated into a single object in Seurat bib49. Based on the workflow described in Kotliarov et al., a distance matrix was generated from cell surface protein features bib27. This matrix was used for shared-nearest-neighbor finding and clustering at resolution=0.5. Neighbor finding and clustering were performed on the integrated gene expression data at a resolution=0.75 and dimensions=1:30. A tSNE (t-distributed stochastic neighbor embedding) was generated from the protein data PCA. Seurat was used to generate a heatmap, dotplot, and featureplots. Differential gene expression testing was performed within each cluster between the high and low ADCP groups using Seurat’s FindMarkers function. ADCP DEG was filtered to genes with >10% expression in either group, a log fold change >0.25, and a Bonferroni p<0.05.
ADCP assay
The antibody effector function ADCP was measured as previously described bib1bib53bib52. Briefly, A244 gp120 Env-coated fluorescent beads were incubated at 37°C for 2 hr with diluted plasma (1:50) collected at week 26, 2 weeks after administration of the RV144 vaccination series. Anti-CD4 monoclonal antibody-treated THP-1 cells (human monocytic cell line; ATCC TIB-202) (treated for 15 min at 4°C) were added to immune complexes and spinoculated for 1 hr at 4°C to allow phagocytosis to occur. Supernatant was removed, cells were washed, and fixed in paraformaldehyde. Phagocytosis was measured by flow cytometry and a phagocytosis score was calculated as follows: phagocytosis score=(% pos*MFI of Sample)/(% pos*MFI of no-antibody PBS control). The HIV-1 CD4 binding-site broadly neutralizing antibody (bnAb), CH31, was used as a positive control, and the influenza receptor binding site-specific bnAb, CH65, was used as a negative control. Results are representative of two independent experiments.
Pathway analyses
Association of the protective gene signature with infection (HVTN 505) or magnitude of median ADCP (RV306) responses were analyzed using the Gene Set Enrichment Analysis (GSEA) method as described previously bib16bib50. GSEA was performed on vaccinated HVTN 505 participants at the visit seven time points, 1 month after the last immunization. RNA-seq was performed on samples prior to infection, but participants were categorized based on their infection status. GSEA was performed on 45 RV306 RNA-seq samples that also had ADCP scores obtained at the week 26 (week 2 after the 4th vaccination) time point. Participants were categorized into high and low ADCP groups based on the median values of ADCP measured in a total of 79 vaccinated participants. The RNA-seq gene expression values at the day 3 and week 2 time points were then analyzed for gene enrichment using a gene set of 200 genes, obtained from the Broad Institute (GSE29618_BCELL_VS_MONOCYTE_DAY7_FLU_VACCINE_DN), between the two groups of samples. The gene signature of interest was considered significantly enriched using a threshold of NES≥1.4 and p<0.001 as described previously bib16. The 178 genes enriched with ADCP or infection status in any of the nine analyses, as well as the 82 genes overlapping in enrichment between the two RV306 time points, were used as search terms in GeneMANIA in the Cytoscape software bib31bib58. We selected connections such as co-expression, co-localization, pathway, and physical interactions, as well as Reactome and MSigDB for Attributes. Zero additional genes and up to 10 additional attributes were found with GO biological process-based weighting. The genes in the nine-analysis network were clustered further using the MCODE algorithm in the clusterMaker2 Cytoscape plugin with default settings bib32. Pathway enrichment analysis of the 63 genes enriched in the RV144 infection analysis was performed using Metascape with default parameters, database v20210201 bib59.
Correlates of protection
Composite GES was computed as the average of standardized expression of normalized enriched genes in the gene signature in different vaccine studies. The samples in each vaccine study were grouped into outcomes after challenge or infection status after immunization bib8bib9bib43. Logistic regression was used for evaluating the association between GES and HIV-1 infection in the RV144 study. The fitting methods accommodate the two-phase sampling design via maximum likelihood estimation bib12. Cumulative HIV-1 incidence curves were plotted for the three subgroups of vaccine recipients defined by tertiles into the lower, middle, and upper third of the GES (Low, Medium, and High subgroups), as well as for the entire placebo group HIV negative at week 24 (N=6267 subjects) for reference. These curves were estimated using the Kaplan-Meier method with inverse probability weighting that accounted for the sampling design. Next, VE for the GES subgroups versus the entire placebo group was estimated as one minus the odds of infection in vaccine recipients with Low/Medium/High response divided by the odds of infection in the entire placebo group HIV-1 negative at week 24 of enrollment in the study. The RV144 prediction analysis was implemented by logistic regression. The data set was randomly split into training and testing sets in a 7:3 ratio, while retaining class distributions within the groups. The training data set consisted of 119 individuals while the test data set consisted of 51 individuals. A logistic regression of GES was fit on to the training data set bib41. The model’s discriminative ability was evaluated by generating a ROC curve and the corresponding AUC on the test data set. The prediction accuracy of the model was also assessed on the test data set. The probability that gives minimum misclassification error was chosen as the cutoff. This process was repeated 1000 times and the distribution of the resulting AUC and accuracy were demonstrated by a histogram with a density curve. Similar analysis was performed using a GES computed from the 32 genes that were significantly associated with HIV acquisition.
Among 121 RV144 participants who became infected during the trial and had their HIV-1 genome sequenced at diagnosis, 43 had GES measurements computed from microarray data bib19bib45. Vaccine and placebo groups were compared overall and after stratifying infections with single HIV-1 founders.
Other statistical analyses
Logistic regression that accounted for the sampling design was used for the univariate analyses of the 63 enriched genes. A radar plot of the significant genes was generated to illustrate OR and 95 % CIs. All ORs were reported per 1-SD increase. Significant genes resulted from univariate logistic regressions of the 63 enriched genes were further analyzed with a multivariate stepwise logistic regression to identify genes that were independently associated with HIV protection. Akaike information criterion was used to identify the optimal set of genes. The expressed enriched genes associated with higher magnitude of ADCP in RV306 at day 3 and 2 weeks post the RV144 vaccine regimen were used to compute the ADCP GES in RV144. Spearman correlation was calculated between the ADCP GES from the two time points and the infection GES, respectively.
For prediction analyses, a GES was computed using the 93 genes enriched at the day 3 time point associating with magnitude of ADCP in RV306. The performance of the classifier was assessed using AUC with 95% CI. This model was then tested at the week 2 time point. The prediction accuracy of the model was also assessed on the week 2 test data set. The probability that gives minimum misclassification error was chosen as the cutoff. Similar analysis was done using the 82 genes overlapping between the 118 enriched genes from week 2 and the 93 enriched genes from day 3 post the 4th RV144 vaccination series that were associated with ADCP in RV306. The average expression values for 82 overlapping genes in RV306 at the day 3 and week 2 post vaccination time points were stratified by ADCP scores to generate a heatmap with the R package pheatmap. Values for each gene were scaled and the resulting z-scores were hierarchically clustered using the ‘complete’ method.
All descriptive and inferential statistical analyses were performed using GraphPad Prism 8 (GraphPad Software) and R 3.6.1 (or later) software packages. Comparison of groups was performed using Mann-Whitney tests or t-tests when assumptions were met. All logistic regression models were adjusted for gender and baseline risk behavior and one significant principal component axis bib24bib41. A two-sided p-value of less than 0.05 was considered significant. The Benjamini and Hochberg method was used to calculate false discovery rate-adjusted p-values for multiple testing corrections.