Replication Study: Transcriptional amplification in tumor cells with elevated c-Myc
- LMichelleLewis1
- MeredithCEdwards1
- ZacharyRMeyers1
- CConoverTalbot2
- HaipingHao2
- DavidBlum1
- Reproducibility Project: Cancer Biology[email protected][email protected]
- ElizabethIorns3
- RachelTsui3
- AlexandriaDenis4
- NicolePerfito3
- TimothyMErrington4
- Reproducibility Project: Cancer Biology
- replication
- metascience
- reproducibility
- c-Myc
- gene expression
- Human
- publisher-id30274
- doi10.7554/eLife.30274
- elocation-ide30274
Abstract
As part of the Reproducibility Project: Cancer Biology, we published a Registered Report (Blum et al., 2015), that described how we intended to replicate selected experiments from the paper ‘Transcriptional amplification in tumor cells with elevated c-Myc’ (Lin et al., 2012). Here we report the results. We found overexpression of c-Myc increased total levels of RNA in P493-6 Burkitt’s lymphoma cells; however, while the effect was in the same direction as the original study (Figure 3E; Lin et al., 2012), statistical significance and the size of the effect varied between the original study and the two different lots of serum tested in this replication. Digital gene expression analysis for a set of genes was also performed on P493-6 cells before and after c-Myc overexpression. Transcripts from genes that were active before c-Myc induction increased in expression following c-Myc overexpression, similar to the original study (Figure 3F; Lin et al., 2012). Transcripts from genes that were silent before c-Myc induction also increased in expression following c-Myc overexpression, while the original study concluded elevated c-Myc had no effect on silent genes (Figure 3F; Lin et al., 2012). Treating the data as paired, we found a statistically significant increase in gene expression for both active and silent genes upon c-Myc induction, with the change in gene expression greater for active genes compared to silent genes. Finally, we report meta-analyses for each result.
Introduction
The Reproducibility Project: Cancer Biology (RP:CB) is a collaboration between the Center for Open Science and Science Exchange that seeks to address concerns about reproducibility in scientific research by conducting replications of selected experiments from a number of high-profile papers in the field of cancer biology (Errington et al., 2014). For each of these papers a Registered Report detailing the proposed experimental designs and protocols for the replications was peer reviewed and published prior to data collection. The present paper is a Replication Study that reports the results of the replication experiments detailed in the Registered Report (Blum et al., 2015) for a 2012 paper by Lin et al., and uses a number of approaches to compare the outcomes of the original experiments and the replications.
In 2012, Lin et al. reported results that the c-Myc transcription factor, a potent oncogene that is frequently overexpressed in a large percentage of cancers, globally amplifies the expression of actively transcribed genes, opposed to regulating specific target genes. Using the P493-6 cell line, a model for MYC activation in Burkitt’s lymphoma, total levels of RNA per cell were reported to increase when c-Myc was highly expressed compared to conditions where c-Myc expression was low. Additionally, active genes in cells with low c-Myc levels were reported to increase in expression upon c-Myc induction, in contrast to genes that were silent under low c-Myc conditions that did not change.
The Registered Report for the 2012 paper by Lin et al. described the experiments to be replicated (Figure 1B and 3E–F), and summarized the current evidence for these findings (Blum et al., 2015). Since that publication there have been additional studies investigating the ability c-Myc to influence the global gene expression output of cells. Similar to Lin et al. other studies have reported c-Myc dependent amplification of cellular RNA (Hart et al., 2014; Hsu et al., 2015; Nie et al., 2012; Sabò et al., 2014), although this observation was not reported in all biological systems (Fagnocchi et al., 2016; Sabò et al., 2014; Walz et al., 2014). It has been suggested c-Myc regulates specific genes that indirectly lead to RNA amplification (Sabò et al., 2014; Sabò and Amati, 2014; Walz et al., 2014). This has also been suggested of MYCN (Duffy et al., 2015). The reported differences could be a result of the intrinsic variation between cell lines in maintaining the transcriptome (Trakhtenberg et al., 2016). Indeed, a recent study reported that distinct transcriptional regulation can be accounted for by differences in promoter affinity under different c-Myc expression levels (Lorenzin et al., 2016).
The outcome measures reported in this Replication Study will be aggregated with those from the other Replication Studies to create a dataset that will be examined to provide evidence about reproducibility of cancer biology research, and to identify factors that influence reproducibility more generally.
Results and discussion
##############################################################################
# The R code in this executable research article is from https://osf.io/tfd57/
# and associated files.
# Only code necessary to reproduce the article is included here.
# See the link above for more details
# Code edited only to remove extraneous outputs and readability
##############################################################################
# Load packages
library(cowplot)
library(ggplot2)
library(lsmeans)
library(reshape)
library(Rmisc)
# Load data
dat <- read.csv("Study_48_Figure_2_Supplemental_Tables.csv", header=T)
data2 <- read.csv("Study_48_Protocol_2_Data.csv", header=T)
comb.means <- read.csv("Study_48_Protocols_3_4_Combined_Means.csv", header=T)
meta <- read.csv("Study_48_Meta_Analysis.csv", header = T)
################################################################################
# Constants from https://osf.io/9wmq8/
zero <- c(4.394, 4.076, 4.286)
one <- c(4.114, 4.286, 3.712)
twentyfour <- c(5.868, 5.112, 5.424)
################################################################################
# Statistical analyses from Study_48_Protocol_2_Analysis.R https://osf.io/u7a5h/
#creates new column calculating RNA in 100uL
data2$RNA.100uL <- data2$Average.RNA.Concentration*100
##calculates RNA per cell
data2$RNA.per.cell <- data2$RNA.100uL/data2$Total.Cells.Harvested
#calculates RNA per 1000 cells
data2$value <- data2$RNA.per.cell*1000
########## Lot 1 Analysis ##########
####################################
#shapiro test for normality on lot 1 data by time
norm1 <- sapply(unique(data2$Time), function(x)
shapiro.test(data2[which(data2$Lot=="1" & data2$Time==x),]$value)) #all data normal
#time as character
data2$Time <- as.character(as.factor((data2$Time)))
#one-way ANOVA comparing total RNA (ng/1000 cells) in cells cultured 0 hr, 1 hr, and 24 hr from tet release.
fit1 <- aov(value ~ Time, data=data2[which(data2$Lot=="1"),])
invisible(ref1 <- lsmeans(fit1, "Time"))
c_list <- list(c1 = c(-1,0,1)) # contrast 0hr to 24 hr
contrast1 <- summary(contrast(ref1, c_list))
########## Lot 2 Analysis ###########
#####################################
#shapiro test for normality on lot 2 data by time
norm2 <- sapply(unique(data2$Time), function(x)
shapiro.test(data2[which(data2$Lot=="2" & data2$Time==x),]$value)) #all data normal
#one-way ANOVA comparing total RNA (ng/1000 cells) in cells cultured 0 hr, 1 hr, and 24 hr from tet release.
fit2 <- aov(value ~ Time, data=data2[which(data2$Lot=="2"),])
invisible(ref2 <- lsmeans(fit2, "Time"))
c_list2 <- list(c2 = c(-1,0,1)) # contrast 0hr to 24 hr
contrast2 <- summary(contrast(ref2, c_list2))
################################################################################
# Subsets on Lot/time/active/silent from https://osf.io/2yj6v/
active_0hr_l1 <- comb.means[which(comb.means$Status=="Active" & comb.means$Measure=="Mean_0HR_C1"),]$final.mean
active_1hr_l1 <- comb.means[which(comb.means$Status=="Active" & comb.means$Measure=="Mean_1HR_C1"),]$final.mean
active_24hr_l1 <- comb.means[which(comb.means$Status=="Active" & comb.means$Measure=="Mean_24HR_C1"),]$final.mean
active_0hr_l2 <- comb.means[which(comb.means$Status=="Active" & comb.means$Measure=="Mean_0HR_C2"),]$final.mean
active_1hr_l2 <- comb.means[which(comb.means$Status=="Active" & comb.means$Measure=="Mean_1HR_C2"),]$final.mean
active_24hr_l2 <- comb.means[which(comb.means$Status=="Active" & comb.means$Measure=="Mean_24HR_C2"),]$final.mean
silent_0hr_l1 <- comb.means[which(comb.means$Status=="Silent" & comb.means$Measure=="Mean_0HR_C1"),]$final.mean
silent_1hr_l1 <- comb.means[which(comb.means$Status=="Silent" & comb.means$Measure=="Mean_1HR_C1"),]$final.mean
silent_24hr_l1 <- comb.means[which(comb.means$Status=="Silent" & comb.means$Measure=="Mean_24HR_C1"),]$final.mean
silent_0hr_l2 <- comb.means[which(comb.means$Status=="Silent" & comb.means$Measure=="Mean_0HR_C2"),]$final.mean
silent_1hr_l2 <- comb.means[which(comb.means$Status=="Silent" & comb.means$Measure=="Mean_1HR_C2"),]$final.mean
silent_24hr_l2 <- comb.means[which(comb.means$Status=="Silent" & comb.means$Measure=="Mean_24HR_C2"),]$final.mean
Conditional expression of c-Myc in the B-cell line P493-6
To test the effects of increased levels of c-Myc on gene expression we used the same human P493-6 B cell line of Burkitt’s lymphoma that contains a conditional tetracycline-repressive MYC transgene (Pajic et al., 2000; Schuhmacher et al., 1999) as the original study. We performed Western blot analysis to confirm c-Myc expression could be reduced to very low levels and then reactivated after removal of tetracycline. This is comparable to what was reported in Figure 1B of Lin et al., 2012 and described in Protocol 1 in the Registered Report (Blum et al., 2015). Since proliferation of P493-6 cells depend on c-Myc expression and the presence of serum (Pajic et al., 2000; Schuhmacher et al., 1999), with serum reported to stimulate a majority of genes independent of c-Myc (Schlosser et al., 2005), we maintained these cells in separate lots of serum to assess whether the results differed. For cells maintained in both lots of serum, treatment with tetracycline resulted in a strong decrease in c-Myc protein levels (Figure 1A). After removal of tetracycline, c-Myc levels increased over time approaching the levels observed in tetracycline-free conditions.
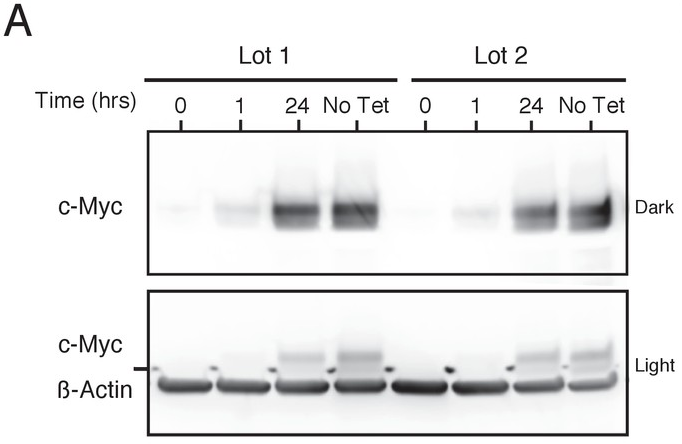
Induction of c-Myc in P493-6 cells and impact on total RNA levels.
P493-6 cells were grown in the presence of tetracycline (Tet) for 72 hr and switched into Tet-free growth medium to induce c-Myc expression. Cells were cultured in two separate lots of serum. (A) Representative Western blot using an anti-c-Myc antibody (top panels) or an anti-ß-Actin antibody (bottom panel). Two exposures of the anti-c-Myc antibody are presented to facilitate detection of c-Myc.
#' @width 17
#' @height 10
#creates new column calculating RNA in 100uL
data2$RNA.100uL <- data2$Average.RNA.Concentration*100
##calculates RNA per cell
data2$RNA.per.cell <- data2$RNA.100uL/data2$Total.Cells.Harvested
#calculates RNA per 1000 cells
data2$value <- data2$RNA.per.cell*1000
#classifies time as character
data2$Time <- as.character(data2$Time)
########## subsets and summarizes Data ##########
#subsets data on lot 1
lot1dat <- data2[which(data2$Lot=="1"),]
#subsets data on lot 2
lot2dat <- data2[which(data2$Lot=="2"),]
#summarizes lot 1 data
lot1sum <- summarySE(data=lot1dat, measurevar = "value", groupvars = "Time")
#summarizes lot 2 data
lot2sum <- summarySE(data=lot2dat, measurevar = "value", groupvars = "Time")
########## Generates bar plot for lot 1 ##########
##################################################
plot.lot1 <- ggplot(lot1sum, aes(x=Time, y=lot1sum$value, fill=Time)) +
geom_bar(stat="identity", width=.8, color = "black") +
geom_errorbar(aes(x=Time, ymin=value-se, ymax=value+se),
width=.20)+
coord_cartesian(ylim=c(0,2.5)) +
scale_fill_manual(values = c("grey30", "grey30","grey30")) +
ylab(expression(paste("Total RNA (ng) \n per 1,000 cells"))) +
scale_y_continuous(expand = c(0,0),
limits = c(0,6),
breaks = c(0, .5, 1.0, 1.5, 2.0, 2.5),
labels = c("0.0", "0.5", "1.0", "1.5", "2.0", "2.5")) +
scale_x_discrete(labels = c("0hr", "1hr", "24hr")) +
theme(plot.margin = unit(c(1,1,1,2), "lines"),
axis.ticks.length = unit(0.25, "cm"),
axis.text.x = element_text(size=15, color = "black"),
axis.text.y = element_text(size = 15, color = "black"),
axis.title.y = element_text(size = 20),
axis.title.x = element_blank(),
panel.background = element_blank(),
axis.line.y = element_line(),
legend.position = "none",
axis.line.x = element_line())
########## Generates bar plot for lot 1 ##########
##################################################
plot.lot2 <- ggplot(lot2sum, aes(x=Time, y=lot2sum$value, fill=Time)) +
geom_bar(stat="identity", width=.8, color = "black") +
geom_errorbar(aes(x=Time, ymin=value-se, ymax=value+se),
width=.20)+
coord_cartesian(ylim=c(0,2.5)) +
scale_fill_manual(values = c("grey30","grey30","grey30")) +
ylab(expression("Total RNA (ng) \n per 1,000 cells")) +
scale_y_continuous(expand = c(0,0),
limits = c(0,6),
breaks = c(0, .5, 1.0, 1.5, 2.0, 2.5),
labels = c("0.0", "0.5", "1.0", "1.5", "2.0", "2.5")) +
scale_x_discrete(labels = c("0hr", "1hr", "24hr")) +
theme(plot.margin = unit(c(1,1,1,2), "lines"),
axis.text.x = element_text(size=15, color = "black"),
axis.text.y = element_text(size = 15, color = "black"),
axis.title.y = element_text(size = 20),
axis.title.x = element_blank(),
panel.background = element_blank(),
axis.line.y = element_line(),
legend.position = "none",
axis.line.x = element_line())
Figure_1B <- plot_grid(plot.lot1, plot.lot2, labels = c("Lot 1", "Lot 2"), label_size = 20, hjust = .01)
Figure_1BInduction of c-Myc in P493-6 cells and impact on total RNA levels.
P493-6 cells were grown in
the presence of tetracycline (Tet) for 72 hr and switched into Tet-free growth medium
to induce c-Myc expression. Cells were cultured in two separate lots of serum. (B) Quantification
of total RNA levels (ng of total RNA per 1,000 cells) for cells at 0, 1, and 24 hr
after release from Tet. Means reported and error bars represent s.e.m. from
length(subset(data2, Lot==1 & Time==0)$value)
summary(fit1)[[1]][["Df"]][1]
summary(fit1)[[1]][["Df"]][2]
round(summary(fit1)[[1]][["F value"]][1],digits=2)
sub('^(-)?0[.]','\\1.', round(summary(fit1)[[1]][["Pr(>F)"]][1],
digits = 3))contrast1$df
round(contrast1$t.ratio,2)
sub('^(-)?0[.]','\\1.',round(contrast1$p.value,3))summary(fit2)[[1]][["Df"]][1]
summary(fit2)[[1]][["Df"]][2]
round(summary(fit2)[[1]][["F value"]][1],digits=2)
sub('^(-)?0[.]','\\1.', round(summary(fit2)[[1]][["Pr(>F)"]][1],
digits = 5))
contrast2$df
round(contrast2$t.ratio,2)
sub('^(-)?0[.]','\\1.',round(contrast2$p.value,4))
Total RNA levels following c-Myc overexpression
We sought to independently
replicate whether increased levels of c-Myc resulted in increased absolute levels of RNA.
This experiment is similar to what was reported in Figure 3E of Lin et al., 2012 and
used the same extraction method for total RNA quantification, which was described in
Protocol 2 in the Registered Report (Blum et al., 2015).
Total RNA was isolated from P493-6 cells 0, 1, and 24 hr after tetracycline release and
the amount of RNA per 1,000 cells was quantified (Figure 1B). We found that under conditions
where c-Myc expression was low (0 hr), there was a mean of round(mean(subset(data2, Lot==1 &
Time==0)$value),2)
length(subset(data2, Lot==1 & Time==0)$value)
formatC(sd(subset(data2, Lot==1 &
Time==0)$value),2,format="f")
round(mean(subset(data2, Lot==1 &
Time==24)$value),2)
length(subset(data2, Lot==1 &
Time==24)$value)
round(sd(subset(data2, Lot==1 &
Time==24)$value),2)
round(mean(subset(data2, Lot==1 & Time==24)$value)/mean(subset(data2,
Lot==1 & Time==0)$value),2)
contrast1$df
round(contrast1$t.ratio,2)
sub('^(-)?0[.]','\\1.',round(contrast1$p.value,3))round(mean(subset(data2, Lot==2 & Time==0)$value),2)
length(subset(data2, Lot==2 &
Time==0)$value)
round(sd(subset(data2, Lot==2 &
Time==0)$value),2)
round(mean(subset(data2, Lot==2 & Time==24)$value),2)
length(subset(data2, Lot==2 &
Time==24)$value)
round(sd(subset(data2, Lot==2 &
Time==24)$value),2)
round(mean(subset(data2, Lot==2 &
Time==24)$value)/mean(subset(data2, Lot==2 & Time==0)$value),2)
contrast2$df
round(contrast2$t.ratio,2)
sub('^(-)?0[.]','\\1.',round(contrast2$p.value,4))round(mean(zero),2)
round(mean(twentyfour),2)
round(mean(twentyfour)/mean(zero),2)
Digital gene expression following c-Myc overexpression
To test whether c-Myc
expression amplifies the existing gene expression program, digital gene expression
analysis using the NanoString nCounter platform was performed on a set of genes from
multiple functional categories. This experiment is similar to what was reported in Figure
3F and Table S1 of Lin et al., 2012 and described in Protocols 3–4 in the
Registered Report (Blum et al., 2015). We quantified mRNA levels/cell of 1369
genes, of which 1212 were the same genes as the 1338 genes interrogated in the original
study. We used the same criteria as the original study to classify a gene as silent
(expression was less than 0.5 transcript/cell at time 0 hr) or active (more than one
transcript/cell at time 0 hr). In cells with low levels of c-Myc (0 hr) there were
length(active_0hr_l1)
formatC(median(active_0hr_l1),2,format="f")length(silent_0hr_l1)
round(median(silent_0hr_l1),3)
round(length(which((active_1hr_l1-active_0hr_l1)>0))/length(active_0hr_l1)*100)
round(length(which((active_24hr_l1-active_0hr_l1)>0))/length(active_0hr_l1)*100)
round(length(which((active_24hr_l1-active_1hr_l1)>0))/length(active_0hr_l1)*100)
round(median(active_1hr_l1)/median(active_0hr_l1),2)
formatC(median(active_24hr_l1)/median(active_0hr_l1),2,format="f")round(median(active_24hr_l1)/median(active_1hr_l1),2)
round(length(which((silent_1hr_l1-silent_0hr_l1)>0))/length(silent_0hr_l1)*100)
round(length(which((silent_24hr_l1-silent_0hr_l1)>0))/length(silent_0hr_l1)*100)
round(length(which((silent_24hr_l1-silent_1hr_l1)>0))/length(silent_0hr_l1)*100)
round(median(silent_1hr_l1)/median(silent_0hr_l1),2)
round(median(silent_24hr_l1)/median(silent_0hr_l1),2)
abs(round((median(silent_24hr_l1)-median(silent_1hr_l1))/(median(silent_24hr_l1)),2))
#' @width 18
#' @height 24
comb.means <- comb.means[which(comb.means$Status!="NA"),] #removes NA status genes
comb.means$lstat <- interaction(comb.means$Time, comb.means$Status) #creates interaction variable between lot and status called 'lstat'
comb.means$Time <- as.character(comb.means$Time) #creates a column for Time
active <- comb.means[which(comb.means$Status=="Active"),] #subsets all data on Active gene status
silent <- comb.means[which(comb.means$Status=="Silent"),] #subsets all data on Silent gene status
#create summary data for graph lot 1
active.sum1 <- summarySE(active[which(active$Lot=="C1"),], measurevar="final.mean", groupvars="Time")
silent.sum1 <- summarySE(silent[which(silent$Lot=="C1"),], measurevar="final.mean", groupvars="Time")
#create summary data for graph lot 2
active.sum2 <- summarySE(active[which(active$Lot=="C2"),], measurevar="final.mean", groupvars="Time")
silent.sum2 <- summarySE(silent[which(silent$Lot=="C2"),], measurevar="final.mean", groupvars="Time")
########## Plots Active Genes/ Lot 1 LOG SCALE ##########
#########################################################
log_activeplot1 <- ggplot(active[which(active$Lot=="C1"),], aes(x=Time, y = final.mean)) +
stat_boxplot(geom ='errorbar', width=0.5) +
geom_boxplot(aes(fill=Time), outlier.shape = 16, outlier.size = 1.5, outlier.colour = "black", colour = "black") +
scale_fill_manual(values=c("red", "red", "red"))+
ylab("Transcripts/Cell") +
ggtitle("Active genes")+
xlab(element_blank()) +
scale_x_discrete(labels=c("0hr", "1hr", "24hr")) +
scale_y_continuous(expand = c(.01,.01),
trans = "log2",
limits = c(2^-10,2^11),
breaks = c( 2^-9,2^-5,2^-1,2^3,2^7,2^11),
labels = c(bquote("2"^"-9"),bquote("2"^"-5"),
bquote("2"^"-1"),bquote("2"^"3"),
bquote("2"^"7"),bquote("2"^"11"))) +
theme_bw()+
theme(legend.position = "none",
axis.ticks.length = unit(0.2, "cm"),
plot.title = element_text(color = "black", size = 15, hjust = .5),
plot.margin = unit(c(1,1,1,1),"cm"),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_rect(colour = "black", size=1.8),
axis.title = element_text(colour = "black", size = 15),
axis.text.x = element_text(colour="black",size=15, margin=margin(.5,.5,.5,.5)),
axis.text.y = element_text(colour="black",size=15, margin=margin(.5,.5,.5,.5), hjust = 0),
axis.title.x = element_blank(),
axis.title.y = element_text(colour="black",size=15,margin = margin(r=10, unit="pt")))
########## Plots Active Genes/ Lot 1 LINEAR SCALE ##########
############################################################
linear_activeplot1 <- ggplot(active[which(active$Lot=="C1" & active$final.mean<=100),], aes(x=Time, y = final.mean)) +
stat_boxplot(geom ='errorbar', width=0.5 ) +
geom_boxplot(aes(fill=Time), outlier.shape = 16, outlier.size = 1.5, outlier.colour = "black", colour = "black") +
scale_fill_manual(values=c("red", "red", "red"))+
ggtitle("Active genes")+
ylab("Transcripts/Cell") +
xlab(element_blank()) +
scale_x_discrete(labels=c("0hr", "1hr", "24hr")) +
scale_y_continuous(expand = c(0,0),
limits = c(-5, 105),
breaks = c(0,20,40,60,80,100)) +
theme_bw()+
theme(legend.position = "none",
axis.ticks.length = unit(0.2, "cm"),
plot.title = element_text(color = "black", size = 15, hjust = .5),
plot.margin = unit(c(1,1,1,1),"cm"),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_rect(colour = "black", size=1.8),
axis.title = element_text(colour = "black", size = 15),
axis.text.x = element_text(colour="black",size=15, margin=margin(.5,.5,.5,.5)),
axis.text.y = element_text(colour="black",size=15, margin=margin(.5,.5,.5,.5), hjust = 0),
axis.title.x = element_blank(),
axis.title.y = element_text(colour="black",size=15,margin = margin(r=10, unit="pt")))
########## Plots Active Genes/ Lot 2 LOG SCALE ##########
#########################################################
log_activeplot2 <- ggplot(active[which(active$Lot=="C2"),], aes(x=Time, y = final.mean)) +
stat_boxplot(geom ='errorbar', width=0.5 ) +
geom_boxplot(aes(fill=Time), outlier.shape = 16, outlier.size = 1.5, outlier.colour = "black", colour = "black") +
scale_fill_manual(values=c("red", "red", "red"))+
ylab("Transcripts/Cell") +
ggtitle("Active genes")+
xlab(element_blank()) +
scale_x_discrete(labels=c("0hr", "1hr", "24hr")) +
scale_y_continuous(expand = c(.01,.01),
trans = "log2",
limits = c(2^-10,2^11),
breaks = c( 2^-9,2^-5,2^-1,2^3,2^7,2^11),
labels = c(bquote("2"^"-9"),bquote("2"^"-5"),
bquote("2"^"-1"),bquote("2"^"3"),
bquote("2"^"7"),bquote("2"^"11"))) +
theme_bw()+
theme(legend.position = "none",
axis.ticks.length = unit(0.2, "cm"),
plot.title = element_text(color = "black", size = 15, hjust = .5),
plot.margin = unit(c(1,1,1,1),"cm"),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_rect(colour = "black", size=1.8),
axis.title = element_text(colour = "black", size = 15),
axis.text.x = element_text(colour="black",size=15, margin=margin(.5,.5,.5,.5)),
axis.text.y = element_text(colour="black",size=15, margin=margin(.5,.5,.5,.5), hjust = 0),
axis.title.x = element_blank(),
axis.title.y = element_text(colour="black",size=15,margin = margin(r=10, unit="pt")))
########## Plots Active Genes/ Lot 2 LINEAR SCALE ##########
############################################################
linear_activeplot2 <- ggplot(active[which(active$Lot=="C2" & active$final.mean<=100),], aes(x=Time, y = final.mean)) +
stat_boxplot(geom ='errorbar', width=0.5 ) +
geom_boxplot(aes(fill=Time), outlier.shape = 16, outlier.size = 1.5, outlier.colour = "black", colour = "black") +
scale_fill_manual(values=c("red", "red", "red"))+
ggtitle("Active genes")+
ylab("Transcripts/Cell") +
xlab(element_blank()) +
scale_x_discrete(labels=c("0hr", "1hr", "24hr")) +
scale_y_continuous(expand = c(0,0),
limits = c(-5, 105),
breaks = c(0,20,40,60,80,100)) +
theme_bw()+
theme(legend.position = "none",
axis.ticks.length = unit(0.2, "cm"),
plot.title = element_text(color = "black", size = 15, hjust = .5),
plot.margin = unit(c(1,1,1,1),"cm"),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_rect(colour = "black", size=1.8),
axis.title = element_text(colour = "black", size = 15),
axis.text.x = element_text(colour="black",size=15, margin=margin(.5,.5,.5,.5)),
axis.text.y = element_text(colour="black",size=15, margin=margin(.5,.5,.5,.5), hjust = 0),
axis.title.x = element_blank(),
axis.title.y = element_text(colour="black",size=15,margin = margin(r=10, unit="pt")))
########## Plots Silent Genes/ Lot 1 LOG SCALE ##########
#########################################################
log_silentplot1 <- ggplot(silent[which(silent$Lot=="C1"),], aes(x=Time, y = final.mean)) +
stat_boxplot(geom ='errorbar', width=0.5 ) +
geom_boxplot(aes(fill=Time), outlier.shape = 16, outlier.size = 1.5, outlier.colour = "black", colour = "black") +
scale_fill_manual(values=c("red", "red", "red"))+
ylab("Transcripts/Cell") +
ggtitle("Silent genes")+
xlab(element_blank()) +
scale_x_discrete(labels=c("0hr", "1hr", "24hr")) +
scale_y_continuous(expand = c(.01,.01),
trans = "log2",
limits = c(2^-10,2^11),
breaks = c( 2^-9,2^-5,2^-1,2^3,2^7,2^11),
labels = c(bquote("2"^"-9"),bquote("2"^"-5"),
bquote("2"^"-1"),bquote("2"^"3"),
bquote("2"^"7"),bquote("2"^"11"))) +
theme_bw()+
theme(legend.position = "none",
axis.ticks.length = unit(0.2, "cm"),
plot.title = element_text(color = "black", size = 15, hjust = .5),
plot.margin = unit(c(1,1,1,1),"cm"),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_rect(colour = "black", size=1.8),
axis.title = element_text(colour = "black", size = 15),
axis.text.x = element_text(colour="black",size=15, margin=margin(.5,.5,.5,.5)),
axis.text.y = element_text(colour="black",size=15, margin=margin(.5,.5,.5,.5), hjust = 0),
axis.title.x = element_blank(),
axis.title.y = element_text(colour="black",size=15,margin = margin(r=10, unit="pt")))
########## Plots Silent Genes/ Lot 1 LINEAR SCALE ##########
############################################################
linear_silentplot1 <- ggplot(silent[which(silent$Lot=="C1" & silent$final.mean<=100),], aes(x=Time, y = final.mean)) +
stat_boxplot(geom ='errorbar', width=0.5 ) +
geom_boxplot(aes(fill=Time), outlier.shape = 16, outlier.size = 1.5, outlier.colour = "black", colour = "black") +
scale_fill_manual(values=c("red", "red", "red"))+
ggtitle("Silent genes")+
ylab("Transcripts/Cell") +
xlab(element_blank()) +
scale_x_discrete(labels=c("0hr", "1hr", "24hr")) +
scale_y_continuous(expand = c(0,0),
limits = c(-5, 105),
breaks = c(0,20,40,60,80,100)) +
theme_bw()+
theme(legend.position = "none",
axis.ticks.length = unit(0.2, "cm"),
plot.title = element_text(color = "black", size = 15, hjust = .5),
plot.margin = unit(c(1,1,1,1),"cm"),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_rect(colour = "black", size=1.8),
axis.title = element_text(colour = "black", size = 15),
axis.text.x = element_text(colour="black",size=15, margin=margin(.5,.5,.5,.5)),
axis.text.y = element_text(colour="black",size=15, margin=margin(.5,.5,.5,.5), hjust = 0),
axis.title.x = element_blank(),
axis.title.y = element_text(colour="black",size=15,margin = margin(r=10, unit="pt")))
########## Plots Silent Genes/ Lot 2 LOG SCALE ##########
#########################################################
#plots active cohort 1
log_silentplot2 <- ggplot(silent[which(silent$Lot=="C2"),], aes(x=Time, y = final.mean)) +
stat_boxplot(geom ='errorbar', width=0.5 ) +
geom_boxplot(aes(fill=Time), outlier.shape = 16, outlier.size = 1.5, outlier.colour = "black", colour = "black") +
scale_fill_manual(values=c("red", "red", "red"))+
ylab("Transcripts/Cell") +
ggtitle("Silent genes")+
xlab(element_blank()) +
scale_x_discrete(labels=c("0hr", "1hr", "24hr")) +
scale_y_continuous(expand = c(.01,.01),
trans = "log2",
limits = c(2^-10,2^11),
breaks = c( 2^-9,2^-5,2^-1,2^3,2^7,2^11),
labels = c(bquote("2"^"-9"),bquote("2"^"-5"),
bquote("2"^"-1"),bquote("2"^"3"),
bquote("2"^"7"),bquote("2"^"11"))) +
theme_bw()+
theme(legend.position = "none",
axis.ticks.length = unit(0.2, "cm"),
plot.title = element_text(color = "black", size = 15, hjust = .5),
plot.margin = unit(c(1,1,1,1),"cm"),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_rect(colour = "black", size=1.8),
axis.title = element_text(colour = "black", size = 15),
axis.text.x = element_text(colour="black",size=15, margin=margin(.5,.5,.5,.5)),
axis.text.y = element_text(colour="black",size=15, margin=margin(.5,.5,.5,.5), hjust = 0),
axis.title.x = element_blank(),
axis.title.y = element_text(colour="black",size=15,margin = margin(r=10, unit="pt")))
########## Plots Silent Genes/ Lot 2 LINEAR SCALE ##########
############################################################
linear_silentplot2 <- ggplot(silent[which(silent$Lot=="C2" & silent$final.mean<=100),], aes(x=Time, y = final.mean)) +
stat_boxplot(geom ='errorbar', width=0.5 ) +
geom_boxplot(aes(fill=Time), outlier.shape = 16, outlier.size = 1.5, outlier.colour = "black", colour = "black") +
scale_fill_manual(values=c("red", "red", "red")) +
ggtitle("Silent genes")+
ylab("Transcripts/Cell") +
xlab(element_blank()) +
scale_x_discrete(labels=c("0hr", "1hr", "24hr")) +
scale_y_continuous(expand = c(0,0),
limits = c(-5, 105),
breaks = c(0,20,40,60,80,100)) +
theme_bw()+
theme(legend.position = "none",
axis.ticks.length = unit(0.2, "cm"),
plot.title = element_text(color = "black", size = 15, hjust = .5),
plot.margin = unit(c(1,1,1,1.88),"cm"),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_rect(colour = "black", size=1.8),
axis.title = element_text(colour = "black", size = 15),
axis.text.x = element_text(colour="black",size=15, margin=margin(.5,.5,.5,.5)),
axis.text.y = element_text(colour="black",size=15, margin=margin(.5,.5,.5,.5), hjust = 0),
axis.title.x = element_blank(),
axis.title.y = element_text(colour="black",size=15,margin = margin(r=10, unit="pt")))
###########################################################################################
###########################################################################################
#plots all comparisons for Lot 1 silent
lot1_silent <- subset(comb.means, comb.means$Lot=="C1" & comb.means$Status=="Silent")
time0 <- subset(lot1_silent, lot1_silent$Time=="0HR")
time1 <- subset(lot1_silent, lot1_silent$Time=="1HR")
time24 <- subset(lot1_silent, lot1_silent$Time=="24HR")
ratio <- c(((log2(time1$final.mean))-(log2(time0$final.mean))),
((log2(time24$final.mean))-(log2(time0$final.mean))),
((log2(time24$final.mean))-(log2(time1$final.mean))))
lot1_silentdat <- as.data.frame(cbind(as.character(lot1_silent[,1]),as.numeric(as.character(ratio))))
lot1_silentdat$V1 <- as.factor(lot1_silentdat$V1)
lot1_silentdat$V3 <- c(rep("diff1",nrow(lot1_silent)/3),rep("diff2",nrow(lot1_silent)/3),rep("diff3",nrow(lot1_silent)/3))
lot1_silentdat$V3 <- as.factor(lot1_silentdat$V3)
lot1_silentdat$V2 <- as.numeric(as.character(lot1_silentdat$V2))
colnames(lot1_silentdat) <- c("Gene","ratio","comparison")
plot_lot1_silent <- ggplot(lot1_silentdat, aes(x=comparison, y = ratio)) +
stat_boxplot(geom ='errorbar', width=0.5) +
geom_boxplot(aes(fill=comparison), outlier.shape = 16, outlier.size = 1.5, outlier.colour = "black", colour = "black") +
scale_fill_manual(values=c("red", "red", "red"))+
ylab("log2 (ratio)") +
xlab(element_blank()) +
scale_x_discrete(labels=c("1 hr vs. \n 0 hr", "24 hr vs. \n 0 hr", "24hr vs. \n 1 hr")) +
scale_y_continuous(expand = c(0,0),
limits = c(-4.5,6.5),
breaks = c(-4, -2, 0, 2, 4, 6),
labels = c("-4","-2","0","2","4","6")) +
geom_hline(yintercept = 0) +
ggtitle("Silent genes")+
theme_bw()+
theme(legend.position = "none",
axis.ticks.length = unit(0.2, "cm"),
plot.title = element_text(color = "black", size = 15, hjust = .5),
plot.margin = unit(c(1,1,1,1),"cm"),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_rect(colour = "black", size=1.8),
axis.title = element_text(colour = "black", size = 15),
axis.text.x = element_text(colour="black",size=15, margin=margin(.5,.5,.5,.5)),
axis.text.y = element_text(colour="black",size=15, margin=margin(.5,.5,.5,.5)),
axis.title.x = element_blank(),
axis.title.y = element_text(colour="black",size=15,margin = margin(r=10, unit="pt")))
####################################################
####################################################
#plots all comparisons for Lot 2 silent
lot2_silent <- subset(comb.means, comb.means$Lot=="C2" & comb.means$Status=="Silent")
time0 <- subset(lot2_silent, lot2_silent$Time=="0HR")
time1 <- subset(lot2_silent, lot2_silent$Time=="1HR")
time24 <- subset(lot2_silent, lot2_silent$Time=="24HR")
ratio <- c(((log2(time1$final.mean))-(log2(time0$final.mean))),
((log2(time24$final.mean))-(log2(time0$final.mean))),
((log2(time24$final.mean))-(log2(time1$final.mean))))
lot2_silentdat <- as.data.frame(cbind(as.character(lot2_silent[,1]),as.numeric(as.character(ratio))))
lot2_silentdat$V1 <- as.factor(lot2_silentdat$V1)
lot2_silentdat$V3 <- c(rep("diff1",nrow(lot2_silent)/3),rep("diff2",nrow(lot2_silent)/3),rep("diff3",nrow(lot2_silent)/3))
lot2_silentdat$V3 <- as.factor(lot2_silentdat$V3)
lot2_silentdat$V2 <- as.numeric(as.character(lot2_silentdat$V2))
colnames(lot2_silentdat) <- c("Gene","ratio","comparison")
plot_lot2_silent <- ggplot(lot2_silentdat, aes(x=comparison, y = ratio)) +
stat_boxplot(geom ='errorbar', width=0.5) +
geom_boxplot(aes(fill=comparison), outlier.shape = 16, outlier.size = 1.5, outlier.colour = "black", colour = "black") +
scale_fill_manual(values=c("red", "red", "red"))+
ylab("log2 (ratio)") +
xlab(element_blank()) +
scale_x_discrete(labels=c("1 hr vs. \n 0 hr", "24 hr vs. \n 0 hr", "24hr vs. \n 1 hr")) +
scale_y_continuous(expand = c(0,0),
limits = c(-4.5,6.5),
breaks = c(-4, -2, 0, 2, 4, 6),
labels = c("-4","-2","0","2","4","6")) +
geom_hline(yintercept = 0) +
ggtitle("Silent genes")+
theme_bw()+
theme(legend.position = "none",
axis.ticks.length = unit(0.2, "cm"),
plot.title = element_text(color = "black", size = 15, hjust = .5),
plot.margin = unit(c(1,1,1,1),"cm"),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_rect(colour = "black", size=1.8),
axis.title = element_text(colour = "black", size = 15),
axis.text.x = element_text(colour="black",size=15, margin=margin(.5,.5,.5,.5)),
axis.text.y = element_text(colour="black",size=15, margin=margin(.5,.5,.5,.5)),
axis.title.x = element_blank(),
axis.title.y = element_text(colour="black",size=15,margin = margin(r=10, unit="pt")))
####################################################
####################################################
#plots all comparisons for Lot 1 active
lot1_active <- subset(comb.means, comb.means$Lot=="C1" & comb.means$Status=="Active")
time0 <- subset(lot1_active, lot1_active$Time=="0HR")
time1 <- subset(lot1_active, lot1_active$Time=="1HR")
time24 <- subset(lot1_active, lot1_active$Time=="24HR")
ratio <- c(((log2(time1$final.mean))-(log2(time0$final.mean))),
((log2(time24$final.mean))-(log2(time0$final.mean))),
((log2(time24$final.mean))-(log2(time1$final.mean))))
lot1_activedat <- as.data.frame(cbind(as.character(lot1_active[,1]),as.numeric(as.character(ratio))))
lot1_activedat$V1 <- as.factor(lot1_activedat$V1)
lot1_activedat$V3 <- c(rep("diff1",nrow(lot1_active)/3),rep("diff2",nrow(lot1_active)/3),rep("diff3",nrow(lot1_active)/3))
lot1_activedat$V3 <- as.factor(lot1_activedat$V3)
lot1_activedat$V2 <- as.numeric(as.character(lot1_activedat$V2))
colnames(lot1_activedat) <- c("Gene","ratio","comparison")
plot_lot1_active <- ggplot(lot1_activedat, aes(x=comparison, y = ratio)) +
stat_boxplot(geom ='errorbar', width=0.5) +
geom_boxplot(aes(fill=comparison), outlier.shape = 16, outlier.size = 1.5, outlier.colour = "black", colour = "black") +
scale_fill_manual(values=c("red", "red", "red"))+
ylab("log2 (ratio)") +
xlab(element_blank()) +
scale_x_discrete(labels=c("1 hr vs. \n 0 hr", "24 hr vs. \n 0 hr", "24hr vs. \n 1 hr")) +
scale_y_continuous(expand = c(0,0),
limits = c(-4.5,6.5),
breaks = c(-4, -2, 0, 2, 4, 6),
labels = c("-4","-2","0","2","4","6")) +
geom_hline(yintercept = 0) +
ggtitle("Active genes")+
theme_bw()+
theme(legend.position = "none",
axis.ticks.length = unit(0.2, "cm"),
plot.title = element_text(color = "black", size = 15, hjust = .5),
plot.margin = unit(c(1,1,1,1),"cm"),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_rect(colour = "black", size=1.8),
axis.title = element_text(colour = "black", size = 15),
axis.text.x = element_text(colour="black",size=15, margin=margin(.5,.5,.5,.5)),
axis.text.y = element_text(colour="black",size=15, margin=margin(.5,.5,.5,.5)),
axis.title.x = element_blank(),
axis.title.y = element_text(colour="black",size=15,margin = margin(r=10, unit="pt")))
####################################################
####################################################
#plots all comparisons for Lot 2 active
lot2_active <- subset(comb.means, comb.means$Lot=="C2" & comb.means$Status=="Active")
time0 <- subset(lot2_active, lot2_active$Time=="0HR")
time1 <- subset(lot2_active, lot2_active$Time=="1HR")
time24 <- subset(lot2_active, lot2_active$Time=="24HR")
ratio <- c(((log2(time1$final.mean))-(log2(time0$final.mean))),
((log2(time24$final.mean))-(log2(time0$final.mean))),
((log2(time24$final.mean))-(log2(time1$final.mean))))
lot2_activedat <- as.data.frame(cbind(as.character(lot2_active[,1]),as.numeric(as.character(ratio))))
lot2_activedat$V1 <- as.factor(lot2_activedat$V1)
lot2_activedat$V3 <- c(rep("diff1",nrow(lot2_active)/3),rep("diff2",nrow(lot2_active)/3),rep("diff3",nrow(lot2_active)/3))
lot2_activedat$V3 <- as.factor(lot2_activedat$V3)
lot2_activedat$V2 <- as.numeric(as.character(lot2_activedat$V2))
colnames(lot2_activedat) <- c("Gene","ratio","comparison")
plot_lot2_active <- ggplot(lot2_activedat, aes(x=comparison, y = ratio)) +
stat_boxplot(geom ='errorbar', width=0.5) +
geom_boxplot(aes(fill=comparison), outlier.shape = 16, outlier.size = 1.5, outlier.colour = "black", colour = "black") +
scale_fill_manual(values=c("red", "red", "red"))+
ylab("log2 (ratio)") +
xlab(element_blank()) +
scale_x_discrete(labels=c("1 hr vs. \n 0 hr", "24 hr vs. \n 0 hr", "24hr vs. \n 1 hr")) +
scale_y_continuous(expand = c(0,0),
limits = c(-4.5,6.5),
breaks = c(-4, -2, 0, 2, 4, 6),
labels = c("-4","-2","0","2","4","6")) +
geom_hline(yintercept = 0) +
ggtitle("Active genes")+
theme_bw()+
theme(legend.position = "none",
axis.ticks.length = unit(0.2, "cm"),
plot.title = element_text(color = "black", size = 15, hjust = .5),
plot.margin = unit(c(1,1,1,1),"cm"),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_rect(colour = "black", size=1.8),
axis.title = element_text(colour = "black", size = 15),
axis.text.x = element_text(colour="black",size=15, margin=margin(.5,.5,.5,.5)),
axis.text.y = element_text(colour="black",size=15, margin=margin(.5,.5,.5,.5)),
axis.title.x = element_blank(),
axis.title.y = element_text(colour="black",size=15, margin = margin(r=10, unit="pt")))
###########################################################################################
###########################################################################################
#combines lot 1 linear scale plots
linear_lot1 <- plot_grid(linear_activeplot1, linear_silentplot1, ncol = 2, align = "h")
#combines lot 2 linear scale plots
linear_lot2 <- plot_grid(linear_activeplot2, linear_silentplot2, ncol = 2, align = "h")
#combines lot 1 log scale plots
log_lot1 <- plot_grid(log_activeplot1, log_silentplot1, ncol = 2, align = "h", labels = c("A","B"))
#combines lot 2 log scale plots
log_lot2 <- plot_grid(log_activeplot2, log_silentplot2, ncol = 2, align = "h", labels = c("E","F"))
#combines lot 1 ratio plots
ratio_lot1 <- plot_grid(plot_lot1_active, plot_lot1_silent, ncol = 2, align = "h", labels = c("C","D"))
#combines lot 2 ratio plots
ratio_lot2 <- plot_grid(plot_lot2_active, plot_lot2_silent, ncol = 2, align = "h", labels = c("G","H"))
#combines Linear Scale Plots
Linear <- plot_grid(linear_lot1,linear_lot2, nrow = 2, align = "h", labels = c("Lot 1","Lot 2"), label_size = 20)
figure_2 <- plot_grid(Linear,ncol = 1,rel_heights = c(0.1,1))
figure_2Digital gene expression analysis.
P493-6 cells grown in the
presence of tetracycline (Tet) for 72 hr for repression of the conditional pmyc-tet construct,
were switched into Tet-free growth medium to induce c-Myc expression. Cells were
cultured in two separate lots of serum. Transcripts/cell estimates from NanoString
nCounter gene expression assays (prettyNum(length(unique(comb.means$Accession)),
big.mark=",")
length(active_0hr_l1)
length(silent_0hr_l1)
length(active_0hr_l2)
length(silent_0hr_l2)
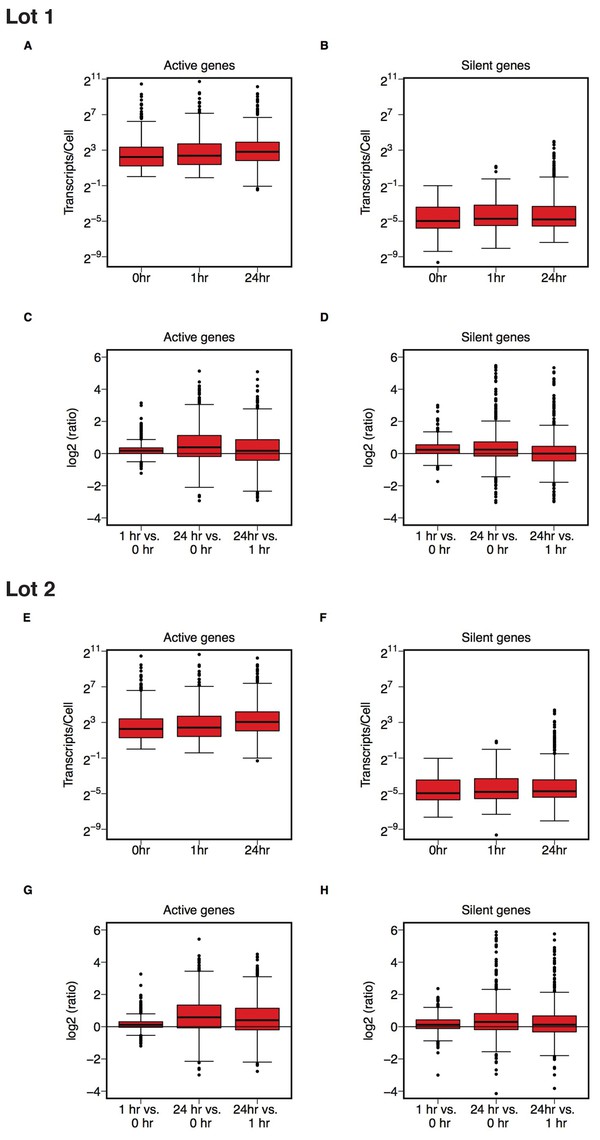
Logarithmic expression of genes.
This is the same experiment as in Figure 2. (A–B, E–F) Gene expression data plotted on a log2 transformed scale for active (A, E) and silent (B, F) genes at 0, 1, and 24 hr after release from Tet for both lots of serum. (C–D, G–H) Box and whisker plots showing gene expression changes (log2 ratio) between the indicated times for active (C, G) and silent (D, H) genes. Median represented as the line through the box and whiskers representing values within 1.5 IQR of the first and third quartile. Additional details for this experiment can be found at https://osf.io/fn2y4/.
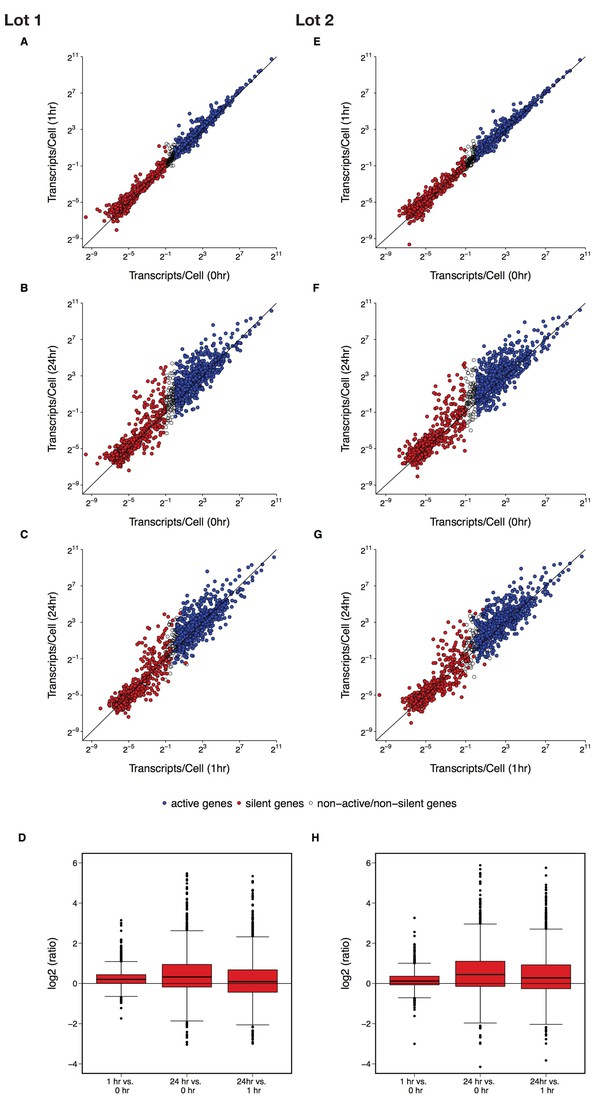
Comparison of gene expression data as continuous.
This is the same experiment as in Figure 2. (A–C, E–G) Scatter plots of log2 transformed gene expression data for all genes analyzed at the indicated times on the y and x axes for both lots of serum. Active genes are blue, silent genes are red, and genes that are neither active or silent (expression was more than 0.5 transcript/cell and less than one transcript/cell at time 0 hr) are white. (D, H) Box and whisker plots showing gene expression changes (log2 ratio) between the indicated times for all genes analyzed for both lots of serum. Median represented as the line through the box and whiskers representing values within 1.5 IQR of the first and third quartile. Additional details for this experiment can be found at https://osf.io/fn2y4/.
To test whether active genes, as well as silent genes, increased expression during c-Myc induction we performed the confirmatory analysis as outlined in the Registered Report (Blum et al., 2015). This analysis differed from what was reported in the original study by analyzing the data as paired instead of unpaired. As suggested during peer review of the Registered Report, this is because expression of the same gene, analyzed across different conditions, is not independent (Blum et al., 2015). We performed a Wilcoxon signed-rank test on active genes comparing expression at 0 hr to 1 hr, 0 hr to 24 hr, and 1 hr to 24 hr, which were statistically significant for cells grown in both lots of serum (Table 1). The same comparisons were performed on silent genes, which were also statistically significant, with the exception of the silent gene comparison of 1 hr to 24 hr for serum lot one. Considering this was not the test reported in the original study, we conducted these paired analyses on the original data to provide a direct comparison. For both active and silent genes c-Myc induction resulted in statistically significant increases in expression, with the exception of the silent gene comparison from 0 hr to 1 hr (Table 1). This is in contrast to the results of the unpaired tests that were reported in the original study where active genes were reported to have a statistically significant increase in expression and silent genes were reported as not statistically significant for all comparisons. We conducted an exploratory unpaired analysis on the replication data for comparison, which resulted in statistically significant differences among the active gene comparisons as well as half of the silent gene comparisons (Table 2).
table1_active <- data.frame(dat[c(1:5)]) #subsets on active genes
table1_active <- melt(table1_active,id.vars = c("Study","Label")) #melts on Study and Label Variables
table1_active$interaction <- interaction(table1_active$Study,table1_active$variable)
table1_active <- reshape(table1_active, idvar="interaction", timevar = "Label",direction="wide")
table1_active <- table1_active[,c(2:4,7,10)]
table1_silent <- data.frame(dat[c(1:2,6:8)]) #subsets on silent genes
table1_silent <- melt(table1_silent,id.vars = c("Study","Label")) #melts on Study and Label Variables
table1_silent$interaction <- interaction(table1_silent$Study,table1_silent$variable)
table1_silent <- reshape(table1_silent, idvar="interaction", timevar = "Label",direction="wide")
table1_silent <- table1_silent[,c(2:4,7,10)]
table1 <- rbind(table1_active,table1_silent) #combines silent and active into one data frame
#changes column names
colnames(table1) <- c("Study","Comparison","Z value","P value","Sample size (n)")
#creates comparison column/ renames comparisons
table1$Comparison <- rep(c(rep("0hr vs 1hr",3),rep("0hr vs 24hr",3),rep("1hr vs 24hr",3)),2)
rownames(table1) <- NULL #deletes row names
table1$Study <- as.character(table1$Study) #Makes 'study' variable as character
table1[c(2:3,5:6,8:9,11:12,14:15,17:18),2] <- c("","")
#label active and silent categories
table1$Genes <- c(c("Active",rep(c(""),8)),c("Silent",rep(c(""),8)))
table1 <- table1[,c(6,2,1,3:5)]
table1| Genes | Comparison | Study | Z value | P value | Sample size (n) |
|---|---|---|---|---|---|
| Active | 0hr vs 1hr | RP:CB Lot 1 | 14.86 | 1.36e-55 | 708 |
| RP:CB Lot 2 | 11.83 | 2.83e-34 | 719 | ||
| Lin et al., 2012 | 21.17 | 1.05e-130 | 755 | ||
| 0hr vs 24hr | RP:CB Lot 1 | 9.922 | 3.67e-24 | 708 | |
| RP:CB Lot 2 | 12.77 | 3.77e-40 | 719 | ||
| Lin et al., 2012 | 23.26 | 3.33e-184 | 755 | ||
| 1hr vs 24hr | RP:CB Lot 1 | 4.742 | 0.00000192 | 708 | |
| RP:CB Lot 2 | 10.04 | 9.91e-25 | 719 | ||
| Lin et al., 2012 | 23.26 | 3.33e-184 | 755 | ||
| Silent | 0hr vs 1hr | RP:CB Lot 1 | 12.61 | 7.11e-40 | 580 |
| RP:CB Lot 2 | 7.05 | 9.29e-13 | 572 | ||
| Lin et al., 2012 | -1.998 | 0.0457 | 274 | ||
| 0hr vs 24hr | RP:CB Lot 1 | 8.328 | 2.22e-17 | 579 | |
| RP:CB Lot 2 | 8.156 | 1.03e-16 | 572 | ||
| Lin et al., 2012 | 3.179 | 0.0014 | 276 | ||
| 1hr vs 24hr | RP:CB Lot 1 | 0.6853 | 0.493 | 580 | |
| RP:CB Lot 2 | 4.436 | 0.00000835 | 573 | ||
| Lin et al., 2012 | 5.806 | 4.11e-9 | 236 |
Confirmatory statistical tests
These confirmatory statistical
tests relate to the data presented in Figure 2. Wilcoxon signed-rank test, which treat the
data as paired, were conducted for the original study (Lin et al., 2012) and this
replication attempt (RP:CB). Uncorrected p values are reported with an a priori significance
threshold of sub('^(-)?0[.]','\\1.',round(0.05/3, digits = 4))
#Subsets on only Wilcoxon Rank-Sum Tests
WilcoxonRS <- dat[c(1,9:12)]
table2_active <- melt(WilcoxonRS,id.vars = c("Study","Label.1")) #melts on Study and Label Variables
table2_active$interaction <- interaction(table2_active$Study,table2_active$variable)
table2_active <- reshape(table2_active, idvar="interaction", timevar = "Label.1",direction="wide")
table2_active <- table2_active[,c(2:4,7,10)]
table2_silent <- data.frame(dat[c(1,9,13:15)]) #subsets on silent genes
table2_silent <- melt(table2_silent,id.vars = c("Study","Label.1")) #melts on Study and Label Variables
table2_silent$interaction <- interaction(table2_silent$Study,table2_silent$variable)
table2_silent <- reshape(table2_silent, idvar="interaction", timevar = "Label.1",direction="wide")
table2_silent <- table2_silent[,c(2:4,7,10)]
table2 <- rbind(table2_active,table2_silent) #combines silent and active into one data frame
#changes column names
colnames(table2) <- c("Study","Comparison","W value","P value","Sample size (n)")
#creates comparison column/ renames comparisons
table2$Comparison <- rep(c(rep("0hr vs 1hr",3),rep("0hr vs 24hr",3),rep("1hr vs 24hr",3)),2)
rownames(table2) <- NULL #deletes row names
table2$Study <- as.character(table2$Study) #Makes 'study' variable as character
table2[c(2:3,5:6,8:9,11:12,14:15,17:18),2] <- c("","")
#label active and silent categories
table2$Genes <- c(c("Active",rep(c(""),8)),c("Silent",rep(c(""),8)))
table2 <- table2[,c(6,2,1,3:5)]
table2| Genes | Comparison | Study | W value | P value | Sample size (n) |
|---|---|---|---|---|---|
| Active | 0hr vs 1hr | RP:CB Lot 1 | 270378 | 0.0103 | 1416 |
| RP:CB Lot 2 | 274696 | 0.0395 | 1438 | ||
| Lin et al., 2012 | 318799 | 0.0001 | 1510 | ||
| 0hr vs 24hr | RP:CB Lot 1 | 300774 | 7.16e-11 | 1416 | |
| RP:CB Lot 2 | 324564 | 4.74e-17 | 1438 | ||
| Lin et al., 2012 | 400999 | 1.16e-42 | 1510 | ||
| 1hr vs 24hr | RP:CB Lot 1 | 281679 | 0.0001 | 1416 | |
| RP:CB Lot 2 | 308954 | 1.45e-10 | 1438 | ||
| Lin et al., 2012 | 372714 | 4.11e-25 | 1510 | ||
| Silent | 0hr vs 1hr | RP:CB Lot 1 | 187682 | 0.0006 | 1160 |
| RP:CB Lot 2 | 174695 | 0.0602 | 1146 | ||
| Lin et al., 2012 | 127104 | 0.236 | 1028 | ||
| 0hr vs 24hr | RP:CB Lot 1 | 185804 | 0.002 | 1160 | |
| RP:CB Lot 2 | 184470 | 0.0003 | 1146 | ||
| Lin et al., 2012 | 132082 | 0.997 | 1028 | ||
| 1hr vs 24hr | RP:CB Lot 1 | 166122 | 0.716 | 1160 | |
| RP:CB Lot 2 | 173608 | 0.0918 | 1146 | ||
| Lin et al., 2012 | 136443 | 0.295 | 1028 |
Exploratory statistical tests
These exploratory statistical tests relate to the data presented in Figure 2. Wilcoxon rank sum tests were conducted for the original study (Lin et al., 2012) and this replication attempt (RP:CB) on the difference in expression of active genes during c-Myc induction (e.g. from 0 hr to 24 hr) compared to the difference in expression of silent genes over that same period (e.g. from 0 hr to 24 hr). Uncorrected p values are reported. Sample sizes reported are based on number of active and silent genes used in the tests. Additional details for this experiment can be found at https://osf.io/fn2y4/.
Importantly, though, the question of whether the change in expression among active genes is different than silent genes has not been tested. This would require a separate test on their difference (Gelman and Stern, 2006; Nieuwenhuis et al., 2011). To test whether active genes increased in expression during c-Myc induction more than silent genes, we performed an exploratory analysis on the difference in expression of active genes during c-Myc induction (e.g. from 0 hr to 24 hr) compared to the difference in expression of silent genes over that same period (e.g. from 0 hr to 24 hr). For both the original and replication data, there was a statistically significant increase in expression of active genes compared to silent genes (Table 3). This suggests that active genes and silent genes do not have similar rates of expression upon c-Myc induction. To summarize, for this experiment we found results that were in the same direction as the original study and suggest that while both active and silent genes increased in expression upon c-Myc induction, the rate of increase was different.
diff <- dat[c(1,16:19)]
# only needed if first column consists of numbers
diff[[1]] <- as.character(diff[[1]])
diff[2,3:5] <- as.character(diff[2,3:5])
table3 <- melt(diff,id.vars = c("Study","Label.2")) #melts on Study and Label Variables
table3$interaction <- interaction(table3$Study,table3$variable)
table3 <- reshape(table3, idvar="interaction", timevar = "Label.2",direction="wide")
table3 <- table3[,c(2:4,7,10)]
#changes column names
colnames(table3) <- c("Study","Comparison","W value","P value","Sample size (n)")
#creates comparison column/ renames comparisons
table3$Comparison <- rep(c(rep("0hr vs 1hr",3),rep("0hr vs 24hr",3),rep("1hr vs 24hr",3)))
rownames(table3) <- NULL #deletes row names
table3$Study <- as.character(table3$Study) #Makes 'study' variable as character
table3[c(2:3,5:6,8:9),2] <- c("","")
table3 <- table3[,c(2,1,3:5)]
table3| Comparison | Study | W value | P value | Sample size (n) |
|---|---|---|---|---|
| 0hr vs 1hr | RP:CB Lot 1 | 303897 | 7.78e-50 | 1288 |
| RP:CB Lot 2 | 278646 | 1.1e-27 | 1292 | |
| Lin et al., 2012 | 349351 | 1.27e-130 | 1269 | |
| 0hr vs 24hr | RP:CB Lot 1 | 272441 | 5.18e-24 | 1288 |
| RP:CB Lot 2 | 292865 | 7.4e-39 | 1292 | |
| Lin et al., 2012 | 368182 | 1.14e-163 | 1269 | |
| 1hr vs 24hr | RP:CB Lot 1 | 235077 | 7.45e-06 | 1288 |
| RP:CB Lot 2 | 272028 | 3.73e-23 | 1292 | |
| Lin et al., 2012 | 332069 | 5.72e-104 | 1269 |
Exploratory statistical tests
These exploratory statistical tests relate to the data presented in Figure 2. Wilcoxon rank sum tests, which treat the data as unpaired, were conducted for the original study (Lin et al., 2012) and this replication attempt (RP:CB). Uncorrected p values are reported. Sample sizes reported are based on treating genes as unpaired between conditions. Additional details for this experiment can be found at https://osf.io/fn2y4/.
The original study and this replication attempt used the same criteria to characterize a gene as silent or active, but there are many negative consequences of dichotomizing continuous variables, such as information loss, especially with a small gene set (Altman and Royston, 2006; Cohen, 1983). Papers published after the original study took an unbiased view by collecting comprehensive RNA-sequencing data to assess if the transcriptional effects of c-Myc were direct or indirect, concluding c-Myc activates and represses transcription of discrete gene sets, which in turn leads to induced RNA amplification (Sabò et al., 2014; Walz et al., 2014). Furthermore, Sabò and colleagues also used NanoString technology to quantify a subset of the differentially expressed genes identified by RNA-seq and observed similar results that revealed upward shifts in gene expression upon c-Myc induction (Sabò et al., 2014). However, instead of dichotomizing genes as active or silent, gene expression data was presented as continuous. Similarly, we presented the digital gene expression data generated during this replication attempt as continuous, which illustrates a general pattern of overall increased gene expression following c-Myc induction (Figure 2—figure supplement 2). Importantly, though, these results are limited to the 1369 genes interrogated in this study and may or may not reflect how the entire transcriptome of P493-6 cells respond to c-Myc induction.
Meta-analyses of original and replicated effects
We performed a meta-analysis using a random-effects model to combine each of the effects described above as pre-specified in the confirmatory analysis plan (Blum et al., 2015). To provide a standardized measure of the effect, a common effect size was calculated for each effect from the original and replication studies. Cohen’s d is the standardized difference between two means using the pooled sample standard deviation. The effect size r is a standardized measure of the strength and direction of the association between two variables, in this case time during c-Myc induction and gene expression. The estimate of the effect size of one study, as well as the associated uncertainty (i.e. confidence interval), compared to the effect size of the other study provides another approach to compare the original and replication results (Errington et al., 2014; Valentine et al., 2011). Importantly, the width of the confidence interval for each study is a reflection of not only the confidence level (e.g. 95%), but also variability of the sample (e.g. SD) and sample size.
The comparison of total RNA levels at low levels of c-Myc (0 hr) compared to high levels of c-Myc (24 hr) resulted in d = 4.19, 95% CI [0.94, 7.37] for the data reported in Figure 3E of the original study (Lin et al., 2012). This compares to d = 0.83, 95% CI [−0.91, 2.48] for serum lot one and d = 4.11, 95% CI [0.90, 7.23] for serum lot two reported in this study. A meta-analysis (Figure 3A) of these effects resulted in d = 2.52, 95% CI [0.01, 5.03], which was statistically significant (p=0.0488). The original and replication results are consistent when considering the direction of the effect, which suggests c-Myc induction increases total RNA levels in P493-6 Burkitt’s lymphoma cells. Noticeably, there was substantial within-study variation observed in this replication attempt, due the different serum lots tested. The point estimate of serum lot one was not within the confidence intervals of the original study and serum lot two, and vice versa; however the point estimate of the original study and serum lot two were within the confidence intervals of each other.
#' @width 40
#' @height 50
#re-orders the data frame
meta <- meta[order(meta$study),]
meta <- meta[order(meta$comparison),]
#subsets data to plot results
d1 <- subset(meta[1:4,]) #Active 0v1
d2 <- subset(meta[5:8,]) #Active 0v24
d3 <- subset(meta[9:12,]) #Active 1v24
d4 <- subset(meta[13:16,]) #Silent 0v1
d5 <- subset(meta[17:20,]) #Silent 0v24
d6 <- subset(meta[21:24,]) #Silent 1v24
d7 <- subset(meta[25:28,]) #protocol 2 oh vs. 24hr
#Plots for protocol 3 analyses:
########################### Active 0hr vs. 1hr #####################################
#re-order the levels for plotting
desired_order <- c("Meta-Analysis","RP:CB Lot 2","RP:CB Lot 1", "Lin et al., 2012" )
#re-orders data for plotting
d1$study <- factor(as.character(d1$study), levels=desired_order)
d1 <- d1[order(d1$study),]
a1 <- ggplot(data=d1,aes(x=estimate,y=d1$study)) +
geom_point(size=5, colour="black", fill = "black", shape = c(22,21,21,23)) +
geom_errorbarh(aes(xmin=CI.lower,xmax=CI.upper, height = .1)) +
geom_vline(xintercept=0,linetype="dashed") +
coord_cartesian(xlim=c(-.2,1)) +
scale_x_continuous(breaks= c(-.2,0,.2,.4,.6,.8,1)) +
ylab(d1$comparison[1])+
xlab(NULL)+
scale_y_discrete(labels = c(paste(as.character(d1$study[1])),
gsub("x", "\n",paste(as.character(d1$study[2]),
paste("x (n =", as.character(d1$N[2]),")"))),
gsub("x", "\n",paste(as.character(d1$study[3]),
paste("x (n =", as.character(d1$N[3]),")"))),
gsub("x", "\n",paste(as.character(d1$study[4]),
paste("x (n =", as.character(d1$N[4]),")"))))) +
theme(panel.background = element_blank(),
axis.ticks.x=element_blank(),
axis.title.x = element_blank(),
axis.text.x = element_blank(),
axis.text.y = element_text(size=15),
legend.position="none",
axis.line.x = element_blank(),
axis.title.y = element_text(size=15,margin=margin(0,30,0,0)),
axis.line.y = element_line(),
plot.margin = unit(c(.5 ,2,.075,.5), "in"))
a1 <- ggdraw(a1)+
draw_text(paste("r","[","L.CI", ",", "U.CI", "]"), x = .84, y = 0.91, fontface="bold")+
draw_text(paste(formatC(d1$estimate[[4]], digits = 2, format = "f"),
"[",
formatC(d1$CI.lower[[4]],digits = 2, format = "f"),
",",
formatC(d1$CI.upper[[4]],digits = 2, format = "f"),
"]"), x = 0.75, y = 0.785, size = 12, hjust=0)+
draw_text(paste(formatC(d1$estimate[[3]], digits = 2, format = "f"),
"[",
formatC(d1$CI.lower[[3]],digits = 2, format = "f"),
",",
formatC(d1$CI.upper[[3]],digits = 2, format = "f"),
"]"), x = 0.75, y = 0.575, size = 12, hjust=0)+
draw_text(paste(formatC(d1$estimate[[2]],digits = 2, format = "f"),
"[",
formatC(d1$CI.lower[[2]],digits = 2, format = "f"),
",",
formatC(d1$CI.upper[[2]],digits = 2, format = "f"),
"]"), x = 0.75, y = 0.3575, size = 12, hjust=0)+
draw_text(paste(formatC(d1$estimate[[1]],digits = 2, format = "f"),
"[",
formatC(d1$CI.lower[[1]],digits = 2, format = "f"),
",",
formatC(d1$CI.upper[[1]],digits = 2, format = "f"),
"]"), x = 0.75, y = 0.154, size = 12, hjust=0)
########################## Active 0hr vs. 24hr #####################################
#re-order the levels for plotting
d2$study <- factor(as.character(d2$study), levels=desired_order)
d2 <- d2[order(d2$study),]
a2 <- ggplot(data=d2,aes(x=estimate,y=d2$study)) +
geom_point(size=5, colour="black", fill = "black", shape = c(22,21,21,23)) +
geom_errorbarh(aes(xmin=CI.lower,xmax=CI.upper, height = .1)) +
geom_vline(xintercept=0,linetype="dashed") +
coord_cartesian(xlim=c(-.2,1)) +
scale_x_continuous(breaks= c(-.2,0,.2,.4,.6,.8,1)) +
ylab(d2$comparison[1])+
xlab(NULL)+
scale_y_discrete(labels = c(paste(as.character(d2$study[1])),
gsub("x", "\n",paste(as.character(d2$study[2]),
paste("x (n =", as.character(d2$N[2]),")"))),
gsub("x", "\n",paste(as.character(d2$study[3]),
paste("x (n =", as.character(d2$N[3]),")"))),
gsub("x", "\n",paste(as.character(d2$study[4]),
paste("x (n =", as.character(d2$N[4]),")")))))+
theme(panel.background = element_blank(),
axis.ticks.x=element_blank(),
axis.title.x = element_blank(),
axis.text.x = element_blank(),
axis.text.y = element_text(size=15),
legend.position="none",
axis.line.x = element_blank(),
axis.title.y = element_text(size=15,margin=margin(0,30,0,0)),
axis.line.y = element_line(),
plot.margin = unit(c(.22,2,.22,.5), "in"))
a2 <- ggdraw(a2)+
draw_text(paste(formatC(d2$estimate[[4]], digits = 2, format = "f"),
"[",
formatC(d2$CI.lower[[4]],digits = 2, format = "f"),
",",
formatC(d2$CI.upper[[4]],digits = 2, format = "f"),
"]"), x = 0.75, y = 0.829, size = 12, hjust=0)+
draw_text(paste(formatC(d2$estimate[[3]], digits = 2, format = "f"),
"[",
formatC(d2$CI.lower[[3]],digits = 2, format = "f"),
",",
formatC(d2$CI.upper[[3]],digits = 2, format = "f"),
"]"), x = 0.75, y = 0.615, size = 12, hjust=0)+
draw_text(paste(formatC(d2$estimate[[2]],digits = 2, format = "f"),
"[",
formatC(d2$CI.lower[[2]],digits = 2, format = "f"),
",",
formatC(d2$CI.upper[[2]],digits = 2, format = "f"),
"]"), x = 0.75, y = 0.395, size = 12, hjust=0)+
draw_text(paste(formatC(d2$estimate[[1]],digits = 2, format = "f"),
"[",
formatC(d2$CI.lower[[1]],digits = 2, format = "f"),
",",
formatC(d2$CI.upper[[1]],digits = 2, format = "f"),
"]"), x = 0.75, y = 0.183, size = 12, hjust=0)
########################### Active 1hr vs. 24hr #####################################
#re-order the levels for plotting
d3$study <- factor(as.character(d3$study), levels=desired_order)
d3 <- d3[order(d3$study),]
a3 <- ggplot(data=d3,aes(x=estimate,y=d3$study))+
geom_point(size=5, colour="black", fill = "black", shape = c(22,21,21,23)) +
geom_errorbarh(aes(xmin=CI.lower,xmax=CI.upper, height = .1)) +
geom_vline(xintercept=0,linetype="dashed") +
coord_cartesian(xlim=c(-.2,1)) +
scale_x_continuous(breaks= c(-.2,0,.2,.4,.6,.8,1)) +
ylab(d3$comparison[1]) +
xlab("r") +
scale_y_discrete(labels = c(paste(as.character(d3$study[1])),
gsub("x", "\n",paste(as.character(d3$study[2]),
paste("x (n =", as.character(d3$N[2]),")"))),
gsub("x", "\n",paste(as.character(d3$study[3]),
paste("x (n =", as.character(d3$N[3]),")"))),
gsub("x", "\n",paste(as.character(d3$study[4]),
paste("x (n =", as.character(d3$N[4]),")"))))) +
theme(panel.background = element_blank(),
legend.position="none",
axis.line.x = element_line(),
axis.title.y = element_text(size=15,margin=margin(0,30,0,0)),
axis.text.y = element_text(size=15),
axis.title.x = element_text(size=15),
axis.line.y = element_line(),
plot.margin = unit(c(.1, 2,0,.5), "in"))
a3 <- ggdraw(a3)+
draw_text(paste(formatC(d3$estimate[[4]], digits = 2, format = "f"),
"[",
formatC(d3$CI.lower[[4]],digits = 2, format = "f"),
",",
formatC(d3$CI.upper[[4]],digits = 2, format = "f"),
"]"), x = 0.75, y = 0.858, size = 12, hjust=0)+
draw_text(paste(formatC(d3$estimate[[3]], digits = 2, format = "f"),
"[",
formatC(d3$CI.lower[[3]],digits = 2, format = "f"),
",",
formatC(d3$CI.upper[[3]],digits = 2, format = "f"),
"]"), x = 0.75, y = 0.6445, size = 12, hjust=0)+
draw_text(paste(formatC(d3$estimate[[2]],digits = 2, format = "f"),
"[",
formatC(d3$CI.lower[[2]],digits = 2, format = "f"),
",",
formatC(d3$CI.upper[[2]],digits = 2, format = "f"),
"]"), x = 0.75, y = 0.432, size = 12, hjust=0)+
draw_text(paste(formatC(d3$estimate[[1]],digits = 2, format = "f"),
"[",
formatC(d3$CI.lower[[1]],digits = 2, format = "f"),
",",
formatC(d3$CI.upper[[1]],digits = 2, format = "f"),
"]"), x = 0.75, y = 0.218, size = 12, hjust=0)
#Plots for protocol 3 analyses Silent genes:
########################### Silent 0hr vs. 1hr #####################################
#re-order the levels for plotting
d4$study <- factor(as.character(d4$study), levels=desired_order)
d4 <- d4[order(d4$study),]
s1 <- ggplot(data=d4,aes(x=estimate,y=d4$study)) +
geom_point(size=5, colour="black", fill = "black", shape = c(22,21,21,23)) +
geom_errorbarh(aes(xmin=CI.lower,xmax=CI.upper, height = .1)) +
geom_vline(xintercept=0,linetype="dashed") +
coord_cartesian(xlim=c(-.2,1)) +
scale_x_continuous(breaks= c(-.2,0,.2,.4,.6,.8,1)) +
ylab(d4$comparison[1])+
xlab(NULL)+
scale_y_discrete(labels = c(paste(as.character(d4$study[1])),
gsub("x", "\n",paste(as.character(d4$study[2]),
paste("x (n =", as.character(d4$N[2]),")"))),
gsub("x", "\n",paste(as.character(d4$study[3]),
paste("x (n =", as.character(d4$N[3]),")"))),
gsub("x", "\n",paste(as.character(d4$study[4]),
paste("x (n =", as.character(d4$N[4]),")")))))+
theme(panel.background = element_blank(),
axis.ticks.x=element_blank(),
axis.title.x = element_blank(),
axis.text.x = element_blank(),
axis.text.y = element_text(size=15),
legend.position="none",
axis.line.x = element_blank(),
axis.title.y = element_text(size=15,margin=margin(0,30,0,0)),
axis.line.y = element_line(),
plot.margin = unit(c(.5 ,2,.075,.5), "in"))
s1 <- ggdraw(s1)+
draw_text(paste("r","[","L.CI", ",", "U.CI", "]"), x = .84, y = 0.91, fontface="bold")+
draw_text(paste(formatC(d4$estimate[[4]], digits = 2, format = "f"),
"[",
formatC(d4$CI.lower[[4]],digits = 2, format = "f"),
",",
formatC(d4$CI.upper[[4]],digits = 2, format = "f"),
"]"), x = 0.75, y = 0.785, size = 12, hjust=0)+
draw_text(paste(formatC(d4$estimate[[3]], digits = 2, format = "f"),
"[",
formatC(d4$CI.lower[[3]],digits = 2, format = "f"),
",",
formatC(d4$CI.upper[[3]],digits = 2, format = "f"),
"]"), x = 0.75, y = 0.575, size = 12, hjust=0)+
draw_text(paste(formatC(d4$estimate[[2]],digits = 2, format = "f"),
"[",
formatC(d4$CI.lower[[2]],digits = 2, format = "f"),
",",
formatC(d4$CI.upper[[2]],digits = 2, format = "f"),
"]"), x = 0.75, y = 0.3575, size = 12, hjust=0)+
draw_text(paste(formatC(d4$estimate[[1]],digits = 2, format = "f"),
"[",
formatC(d4$CI.lower[[1]],digits = 2, format = "f"),
",",
formatC(d4$CI.upper[[1]],digits = 2, format = "f"),
"]"), x = 0.75, y = 0.154, size = 12, hjust=0)
########################## Silent 0hr vs. 24hr #####################################
#re-order the levels for plotting
d5$study <- factor(as.character(d5$study), levels=desired_order)
d5 <- d5[order(d5$study),]
s2 <- ggplot(data=d5,aes(x=estimate,y=d5$study)) +
geom_point(size=5, colour="black", fill = "black", shape = c(22,21,21,23)) +
geom_errorbarh(aes(xmin=CI.lower,xmax=CI.upper, height = .1)) +
geom_vline(xintercept=0,linetype="dashed") +
coord_cartesian(xlim=c(-.2,1)) +
scale_x_continuous(breaks= c(-.2,0,.2,.4,.6,.8,1)) +
ylab(d5$comparison[1])+
xlab(NULL)+
scale_y_discrete(labels = c(paste(as.character(d5$study[1])),
gsub("x", "\n",paste(as.character(d5$study[2]),
paste("x (n =", as.character(d5$N[2]),")"))),
gsub("x", "\n",paste(as.character(d5$study[3]),
paste("x (n =", as.character(d5$N[3]),")"))),
gsub("x", "\n",paste(as.character(d5$study[4]),
paste("x (n =", as.character(d5$N[4]),")")))))+
theme(panel.background = element_blank(),
axis.ticks.x=element_blank(),
axis.title.x = element_blank(),
axis.text.x = element_blank(),
axis.text.y = element_text(size=15),
legend.position="none",
axis.line.x = element_blank(),
axis.title.y = element_text(size=15,margin=margin(0,30,0,0)),
axis.line.y = element_line(),
plot.margin = unit(c(.22,2,.22,.5), "in"))
s2 <- ggdraw(s2)+
draw_text(paste(formatC(d5$estimate[[4]], digits = 2, format = "f"),
"[",
formatC(d5$CI.lower[[4]],digits = 2, format = "f"),
",",
formatC(d5$CI.upper[[4]],digits = 2, format = "f"),
"]"), x = 0.75, y = 0.829, size = 12, hjust=0)+
draw_text(paste(formatC(d5$estimate[[3]], digits = 2, format = "f"),
"[",
formatC(d5$CI.lower[[3]],digits = 2, format = "f"),
",",
formatC(d5$CI.upper[[3]],digits = 2, format = "f"),
"]"), x = 0.75, y = 0.615, size = 12, hjust=0)+
draw_text(paste(formatC(d5$estimate[[2]],digits = 2, format = "f"),
"[",
formatC(d5$CI.lower[[2]],digits = 2, format = "f"),
",",
formatC(d5$CI.upper[[2]],digits = 2, format = "f"),
"]"), x = 0.75, y = 0.395, size = 12, hjust=0)+
draw_text(paste(formatC(d5$estimate[[1]],digits = 2, format = "f"),
"[",
formatC(d5$CI.lower[[1]],digits = 2, format = "f"),
",",
formatC(d5$CI.upper[[1]],digits = 2, format = "f"),
"]"), x = 0.75, y = 0.183, size = 12, hjust=0)
########################## Silent 1hr vs. 24hr #####################################
#re-order the levels for plotting
d6$study <- factor(as.character(d6$study), levels=desired_order)
d6 <- d6[order(d6$study),]
s3 <- ggplot(data=d6,aes(x=estimate,y=factor(d6$study)))+
geom_point(size=5, colour="black", fill = "black", shape = c(22,21,21,23)) +
geom_errorbarh(aes(xmin=CI.lower,xmax=CI.upper, height = .1)) +
geom_vline(xintercept=0,linetype="dashed") +
coord_cartesian(xlim=c(-.2,1)) +
scale_x_continuous(breaks= c(-.2,0,.2,.4,.6,.8,1)) +
ylab(d6$comparison[1]) +
xlab("r") +
scale_y_discrete(labels = c(paste(as.character(d6$study[1])),
gsub("x", "\n",paste(as.character(d6$study[2]),
paste("x (n =", as.character(d6$N[2]),")"))),
gsub("x", "\n",paste(as.character(d6$study[3]),
paste("x (n =", as.character(d6$N[3]),")"))),
gsub("x", "\n",paste(as.character(d6$study[4]),
paste("x (n =", as.character(d6$N[4]),")"))))) +
theme(panel.background = element_blank(),
legend.position="none",
axis.line.x = element_line(),
axis.title.y = element_text(size=15,margin=margin(0,30,0,0)),
axis.text.y = element_text(size=15),
axis.title.x = element_text(size=15),
axis.line.y = element_line(),
plot.margin = unit(c(.1, 2,0,.5), "in"))
s3 <- ggdraw(s3)+
draw_text(paste(formatC(d6$estimate[[4]], digits = 2, format = "f"),
"[",
formatC(d6$CI.lower[[4]],digits = 2, format = "f"),
",",
formatC(d6$CI.upper[[4]],digits = 2, format = "f"),
"]"), x = 0.75, y = 0.858, size = 12, hjust=0)+
draw_text(paste(formatC(d6$estimate[[3]], digits = 2, format = "f"),
"[",
formatC(d6$CI.lower[[3]],digits = 2, format = "f"),
",",
formatC(d6$CI.upper[[3]],digits = 2, format = "f"),
"]"), x = 0.75, y = 0.6445, size = 12, hjust=0)+
draw_text(paste(formatC(d6$estimate[[2]],digits = 2, format = "f"),
"[",
formatC(d6$CI.lower[[2]],digits = 2, format = "f"),
",",
formatC(d6$CI.upper[[2]],digits = 2, format = "f"),
"]"), x = 0.75, y = 0.432, size = 12, hjust=0)+
draw_text(paste(formatC(d6$estimate[[1]],digits = 2, format = "f"),
"[",
formatC(d6$CI.lower[[1]],digits = 2, format = "f"),
",",
formatC(d6$CI.upper[[1]],digits = 2, format = "f"),
"]"), x = 0.75, y = 0.218, size = 12, hjust=0)
########################## Protocol 2 Meta Analysis #####################################
#re-order the levels for plotting
d7$study <- factor(as.character(d7$study), levels=desired_order)
d7 <- d7[order(d7$study),]
pro2 <- ggplot(data=d7,aes(x=estimate,y=d7$study))+
geom_point(size=5, colour="black", fill = "black", shape = c(22,21,21,23)) +
geom_errorbarh(aes(xmin=CI.lower,xmax=CI.upper, height = .1)) +
geom_vline(xintercept=0,linetype="dashed") +
coord_cartesian(xlim=c(-1,8)) +
scale_x_continuous(breaks= c(-1,0,1,2,3,4,5,6,7,8)) +
ylab(d7$comparison[1]) +
xlab("Cohen's"~italic("d")) +
scale_y_discrete(labels = c(paste(as.character(d7$study[1])),
gsub("x", "\n",paste(as.character(d7$study[2]),
paste("x (n =", as.character(d7$N[2]),")"))),
gsub("x", "\n",paste(as.character(d7$study[3]),
paste("x (n =", as.character(d7$N[3]),")"))),
gsub("x", "\n",paste(as.character(d7$study[4]),
paste("x (n =", as.character(d7$N[4]),")"))))) +
theme(panel.background = element_blank(),
legend.position="none",
axis.line.x = element_line(),
axis.title.y = element_text(size=15,margin=margin(0,30,0,0)),
axis.text.y = element_text(size=15),
axis.line.y = element_line(),
plot.margin = margin(.6, 8, .5, .55, "in"))
pro2 <- ggdraw(pro2)+
draw_text(paste("Cohen's d","[","L.CI", ",", "U.CI", "]"), x = 0.568, y = 0.93, fontface="bold") +
draw_text(paste(formatC(d7$estimate[[4]], digits = 2, format = "f"),
"[",
formatC(d7$CI.lower[[4]],digits = 2, format = "f"),
",",
formatC(d7$CI.upper[[4]],digits = 2, format = "f"),
"]"), x = 0.52, y = 0.79, size = 12, hjust=0)+
draw_text(paste(formatC(d7$estimate[[3]], digits = 2, format = "f"),
"[",
formatC(d7$CI.lower[[3]],digits = 2, format = "f"),
",",
formatC(d7$CI.upper[[3]],digits = 2, format = "f"),
"]"), x = 0.52, y = 0.62, size = 12, hjust=0)+
draw_text(paste(formatC(d7$estimate[[2]],digits = 2, format = "f"),
"[",
formatC(d7$CI.lower[[2]],digits = 2, format = "f"),
",",
formatC(d7$CI.upper[[2]],digits = 2, format = "f"),
"]"), x = 0.52, y = 0.455, size = 12, hjust=0)+
draw_text(paste(formatC(d7$estimate[[1]],digits = 2, format = "f"),
"[",
formatC(d7$CI.lower[[1]],digits = 2, format = "f"),
",",
formatC(d7$CI.upper[[1]],digits = 2, format = "f"),
"]"), x = 0.52, y = 0.285, size = 12, hjust=0)
#Creates figure for protocol 3 meta-analyses
pro3 <- plot_grid(a1, s1, a2, s2, a3, s3, nrow = 3)
figure <- plot_grid(pro2, pro3, nrow = 2, rel_heights = c(1,3), labels = c("A", "B"), label_size = 25)
figure_3 <- plot_grid(figure,ncol = 1,rel_heights = c(0.1,1))
figure_3Meta-analyses of each effect.
Effect size and 95% confidence interval are presented for Lin et al., 2012, this replication study (RP:CB), and a random effects meta-analysis of those two effects. Cohen’s d is the standardized difference between the two measurements, with a larger positive value indicating total RNA levels are increased at 24 hr compared to 0 hr. The effect size r is a standardized measure of the correlation (strength and direction) of the association between gene expression and c-Myc induction, with a larger positive value indicating gene expression increased during the course of c-Myc induction. Sample sizes used in Lin et al., 2012 and this replication attempt are reported under the study name. (A) Total RNA levels in P493-6 cells 0 hr compared to 24 hr after release from tetracycline (meta-analysis p = 0.0488). (B) Gene expression of active or silent genes are shown for all comparisons. Active genes: 0 hr compared to 1 hr (meta-analysis p = 1.12x10-7), 0 hr compared to 24 hr (meta-analysis p = 7.01x10-4), 1 hr compared to 24 hr (meta-analysis p = 0.0129). Silent genes: 0 hr compared to 1 hr (meta-analysis p = 0.203), 0 hr compared to 24 hr (meta-analysis p = 7.10x10-17), 1 hr compared to 24 hr (meta-analysis p = 0.0571). Additional details for these meta-analyses can be found at https://osf.io/5yscz/.
There were six comparisons of the gene expression data, three for active genes and three for silent genes (Figure 3B). These calculations were performed analyzing the data as paired, for reasons discussed above and as prespecified in the Registered Report (Blum et al., 2015). For active genes, expression at 0 hr to 1 hr, 0 hr to 24 hr, and 1 hr to 24 hr the meta-analyses were statistically significant (p=1.12×10−7, p=7.01×10−4, p=0.0129, respectively). In all comparisons the results were consistent when considering the direction of the effect; however the effect size point estimate of each study (original, replication serum lot one, replication serum lot two) was not within the confidence interval of the other studies. Further, the large confidence intervals of the meta-analysis along with statistically significant Cochran’s Q tests suggest heterogeneity between the original and replication studies. For silent genes, the meta-analysis was not statistically significant for gene expression at 0 hr to 1 hr and 1 hr to 24 hr (p=0.203, p=0.0571, respectively) and the effect size point estimate of each study was not within the confidence interval of the other studies. Similar to the active gene comparisons, the large confidence intervals of the meta-analysis along with statistically significant Cochran’s Q tests suggest heterogeneity between the studies. Furthermore, for the 0 hr to 1 hr comparison the original study and replication studies were in opposite directions, while the 1 hr to 24 hr comparison was consistent. Finally, the comparison between 0 hr and 24 hr for silent genes was consistent when considering direction of the effect with a statistically significant meta-analysis (p=7.10×10−17). The point estimate of the original study was not within the confidence intervals of the replication studies; however both replication studies with different serum lots were within the confidence intervals of the original study and each other. Overall, the gene expression analysis indicates that the effect sizes observed from the two serum lots tested in this replication attempt, although not identical, were more similar to each other than to the original study.
This direct replication provides an opportunity to understand the present evidence of these effects. Any known differences, including reagents and protocol differences, were identified prior to conducting the experimental work and described in the Registered Report (Blum et al., 2015). However, this is limited to what was obtainable from the original paper and through communication with the original authors, which means there might be particular features of the original experimental protocol that could be critical, but unidentified. So while some aspects, such as the cell line, induction time course, and the method used to measure gene expression were maintained, others were changed at the time of study design (Blum et al., 2015) that could affect results, such as the analytical approach (Silberzahn et al., 2017) and serum lot (Leek et al., 2010). Furthermore, other aspects were unknown or not easily controlled for. These include variables such as cell line genetic drift (Hughes et al., 2007; Kleensang et al., 2016) or changes in cellular volume that can impact overall transcript abundance (Padovan-Merhar et al., 2015). Whether these or other factors influence the outcomes of this study is open to hypothesizing and further investigation, which is facilitated by direct replications and transparent reporting.
Materials and methods
As described in the Registered Report (Blum et al., 2015), we attempted a replication of the experiments reported in Figures 1B and 3E-F of Lin et al., 2012. A detailed description of all protocols can be found in the Registered Report (Blum et al., 2015). Additional detailed experimental notes, data, and analysis are available on the Open Science Framework (OSF) (RRID:SCR_003238) (https://osf.io/mokeb/; Lewis et al., 2017). This includes the R Markdown file (https://osf.io/vdrsh/) that was used to compose this manuscript, which is a reproducible document linking the results in the article directly to the data and code that produced them (Hartgerink, 2017).
Cell culture
P493-6 cells (shared by Young lab, Whitehead Institute for Biomedical Research, RRID: CVCL_6783) were maintained in RPMI-1640 supplemented with 1% Ala-Gln and 10% tetracycline-free FBS (Clontech, Mountain View, CA, cat# 631105, lot# 1: A15003, lot# 2: A15032). Cells were grown at 37°C in a humidified atmosphere at 5% CO2. Quality control data for the cell line are available at https://osf.io/e6ftz/. This includes results confirming the cell line was free of mycoplasma contamination (DDC Medical, Fairfield, Ohio). Additionally, STR DNA profiling of the cell line was performed (DDC Medical, Fairfield, Ohio).
For repression of the conditional pmyc-tet construct in P493-6 cells, 0.1 µg/ml tetracycline (Sigma-Aldrich, St. Louis, MO, cat# T7660) was added to the culture medium and cells were incubated for 72 hr. Under these conditions, P493-6 cells did not proliferate due to a dependency on the expression of MYC (Schuhmacher et al., 1999). For MYC re-induction, cells were washed three times with growth medium and grown in tetracycline-free culture conditions.
Western blot
P493-6 cells were harvested at the indicated times and total cell lysates were prepared by pelleting ~1×107 cells (determined with a C-chip disposable hemocytometer) at 4°C at 1,200 rpm for 5 min using a refrigerated centrifuge (Eppendorf, Westbury, NY, model# 5810R). After cell pellets were washed once with ice-cold 1X PBS, pellets were resuspended in RIPA lysis buffer containing 2X SIGMAFAST Protease inhibitors and 2X Phosphatase inhibitor cocktails 2 and 3. Protein concentrations were determined using the Bradford assay according to the manufacturer’s instructions. Sample buffer was added to protein lysates and 50 µg of protein along with protein ladder was resolved by SDS-PAGE and transferred to PVDF membrane as described in the Registered Report (Blum et al., 2015). The membrane was blocked with 5% w/v nonfat dry milk in 1X TBS with 0.2% Tween-20 (TBST). Membranes were probed with rabbit anti-c-Myc [clone Y69] (Epitomics, Burlingame, CA, cat# 1472–1; RRID:AB_731658); 1:5000 dilution in 5% w/v nonfat dry milk/TBST and mouse anti-ß-actin [clone AC-15] (Sigma-Aldrich, cat# A5441; RRID:AB_476744); 1:10,000 dilution in 5% w/v nonfat dry milk/TBST. Each incubation was followed by washes with TBST and the appropriate secondary antibody: HRP-conjugated donkey anti-rabbit (Sigma-Aldrich, cat# GERPN2124); 1:10,000 dilution in 5% w/v nonfat dry milk/TBST or HRP-conjugated sheep anti-mouse (Sigma-Aldrich, cat# GERPN2124); 1:10,000 dilution in 5% w/v nonfat dry milk/TBST. Membranes were washed with TBST and incubated with ECL Prime Chemiluminescent reagent (Sigma-Aldrich, cat# GERPN2232) according to the manufacturer’s instructions. Western blot images were acquired with G:BOX iChem XT and GeneSnap software (RRID:SCR_014249), version 7.12.02 (Syngene, Frederick, Maryland) and quantified using ImageJ software (RRID:SCR_003070), version 1.50i (Schneider et al., 2012). All images taken are available at https://osf.io/ujg7t/.
RNA quantification
P493-6 cells were harvested at the indicated times and total RNA extraction was performed by pelleting ~1×107 cells (exact number determined with a C-chip disposable hemocytometer) and homogenizing the sample in 1 ml Tri Reagent (Sigma-Aldrich, cat# T9424) according to the manufacturer’s instructions. For each sample 10% v/v miRNA Homogenate Additive was added, vortexed, and incubated on ice for 10 min. For each 1 ml of Tri Reagent, 100 µl of bromochloropropane was added, vortexed for 15–30 s, incubated for 5 min at RT, then centrifuged at 12,000xg for 10 min at 4°C. The aqueous phase was recovered and total RNA isolation was performed using the miRVana miRNA extraction kit (Ambion, Waltham, MA, cat# AM1561) according to the manufacturer’s instructions. Recovered RNA was eluated in 100 µl nuclease-free water. Total RNA concentrations and purity (data available at https://osf.io/jh5r4/) were measured using a NanoDrop ND-1000 (Thermo Fisher Scientific, Waltham, Massachusetts) with the NanoDrop Operating Software, version 3.3, and converted to ng per 1,000 cells.
RNA extraction and NanoString nCounter digital gene expression assay
P493-6 cells were harvested at
the indicated times and 1 × 106 cells were collected (number
determined with a C-chip disposable hemocytometer) and lysed directly in 100 µl Buffer RLT
(Qiagen, Hilden, Germany, cat# 79216) supplemented with ß-mercaptoethanol to yield a
concentration of 10,000 cells per µl. This was performed four independent times. Multiple
4 µl aliquots were stored and shipped at −80°C with temperature monitored during shipping
to avoid freeze/thaw cycles. Lysates were processed according to the Cell Lysate Protocol
(nCounter Gene Expression Assay Manual, NanoString Technologies, Seattle, Washington)
according to the manufacturer’s instructions and as described in the Registered Report
(Blum et al.,
2015). Three nCounter Reporter CodeSets (nCounter GX Human Immunology Kit,
nCounter GX Human Kinase Kit, nCounter Custom CodeSet) encompassing
prettyNum(length(unique(comb.means$Accession)),
big.mark=",")
Statistical analysis
Statistical analysis was performed with R software (RRID:SCR_001905), version 3.3.2 (, 2017). All data, csv files, and analysis scripts are available on the OSF (https://osf.io/mokeb/). Confirmatory statistical analysis was pre-registered (https://osf.io/nj8wb/) before the experimental work began as outlined in the Registered Report (Blum et al., 2015). Proposed analysis of gene expression data was conducted by the Wilcoxon signed-rank test using the method proposed by Pratt to handle zero differences (Pratt, 1959), with additional exploratory analysis performed using the Wilcoxon rank sum test as reported in the original study and a Wilcoxon rank sum test on the difference in expression of active genes during c-Myc induction (e.g. from 0 hr to 24 hr) compared to the difference in expression of silent genes over that same period (e.g. from 0 hr to 24 hr). Data were checked to ensure assumptions of statistical tests were met. When described in the results, the Bonferroni correction, to account for multiple testings, was applied to the alpha error by dividing the uncorrected value (.05) by the number of tests performed. Although the Bonferroni method is conservative, it was accounted for in the power calculations to ensure sample size was sufficient. In cases where the number of groups were three and the sample sizes were evenly distributed among the groups, Fisher's LSD test was performed resulting in an a priori significance threshold of. 05. A meta-analysis of a common original and replication effect size was performed with a random effects model and the metafor package (Viechtbauer, 2010) (available at: https://osf.io/5yscz/). The sample sizes reported in Table 1 and Figure 3 for the gene analysis comparisons is based on the sample size used in the Wilcoxon signed-rank test, which removes samples with zero differences after ranking (Pratt, 1959). The raw original study data were shared by the original authors with the summary data published in the Registered Report (Blum et al., 2015) and was used in the power calculations to determine the sample size for this study.
Deviations from registered report
The number of flasks, and thus cells, was increased when tetracycline was added to P493-6 cells to account for the cells not proliferating during this period (i.e. there were two Flask B’s as described in the Registered Report, which were pooled prior to seeding). The proposed statistical analysis for the western blot analysis (Protocol 1) described in the Registered Report was not performed since the levels of normalized c-Myc at time 0 hr was at the limit of detection. The number of genes analyzed in the original study, and thus listed in the Registered Report, was reported incorrectly as 1388 instead of 1338 (data shared by original authors). NanoString analysis was conducted using the nCounter RCC Collector Worksheet instead of nSolver Analysis software. Additionally, the statistical tests reported in Figure 3F of the original study incorrectly described the comparisons as between 0 hr and 1 hr instead of between 0 hr and 24 hr (scripts shared by original authors). The corrected values are described above for comparisons and used in the meta-analysis. Additional materials and instrumentation not listed in the Registered Report, but needed during experimentation are also listed.
References
-
- DGAltman
- PRoyston
-
- RBiggs
- RLMacmillan
-
- DBlum
- HHao
- MMcCarthy
-
- JCohen
-
- DJDuffy
- AKrstic
- MHalasz
- TSchwarzl
- DFey
- KIljin
- JPMehta
- KKillick
- JWhilde
- BTurriziani
- SHaapa-Paananen
- VFey
- MFischer
- FWestermann
- K-OHenrich
- SBannert
- DGHiggins
- WKolch
-
- TMErrington
- EIorns
- WGunn
- FETan
- JLomax
- BANosek
-
- LFagnocchi
- ACherubini
- HHatsuda
- AFasciani
- SMazzoleni
- VPoli
- VBerno
- RLRossi
- RReinbold
- MEndele
- TSchroeder
- MRocchigiani
- ŻSzkarłat
- SOliviero
- SDalton
- AZippo
-
- AGelman
- HStern
-
- JRHart
- TCRoberts
- MSWeinberg
- KVMorris
- PKVogt
-
- CHJHartgerink
-
- LRHiorns
- TDBradshaw
- LASkelton
- QYu
- LRKelland
- BLeyland-Jones
-
- TYHsu
- LMSimon
- NJNeill
- RMarcotte
- ASayad
- CSBland
- GVEcheverria
- TSun
- SJKurley
- STyagi
- KLKarlin
- RDominguez-Vidaña
- JDHartman
- ARenwick
- KScorsone
- RJBernardi
- SOSkinner
- AJain
- MOrellana
- CLagisetti
- IGolding
- SYJung
- JRNeilson
- XHZhang
- TACooper
- TRWebb
- BGNeel
- CAShaw
- TFWestbrook
-
- PHughes
- DMarshall
- YReid
- HParkes
- CGelber
-
- AKleensang
- MMVantangoli
- SOdwin-DaCosta
- MEAndersen
- KBoekelheide
- MBouhifd
- AJFornace
- HHLi
- CBLivi
- SMadnick
- AMaertens
- MRosenberg
- JDYager
- LZhaog
- THartung
-
- JTLeek
- RBScharpf
- HCBravo
- DSimcha
- BLangmead
- WEJohnson
- DGeman
- KBaggerly
- RAIrizarry
-
- LMLewis
- MCEdwards
- ZRMeyers
- CCTalbot
- HHao
- DBlum
- EIorns
- RTsui
- ADenis
- NPerfito
- TMErrington
-
- CYLin
- JLovén
- PBRahl
- RMParanal
- CBBurge
- JEBradner
- TILee
- RAYoung
-
- FLorenzin
- UBenary
- ABaluapuri
- SWalz
- LAJung
- BEyss
- CKisker
- JWolf
- MEilers
- EWolf
-
- ZNie
- GHu
- GWei
- KCui
- AYamane
- WResch
- RWang
- DRGreen
- LTessarollo
- RCasellas
- KZhao
- DLevens
-
- LNielson
- GSmyth
- PGreenfield
-
- SNieuwenhuis
- BUForstmann
- EJWagenmakers
-
- OPadovan-Merhar
- GPNair
- AGBiaesch
- AMayer
- SScarfone
- SWFoley
- ARWu
- LSChurchman
- ASingh
- ARaj
-
- APajic
- DSpitkovsky
- BChristoph
- BKempkes
- MSchuhmacher
- MSStaege
- MBrielmeier
- JEllwart
- FKohlhuber
- GWBornkamm
- APolack
- DEick
-
- JWPratt
-
-
- ASabò
- BAmati
-
- ASabò
- TRKress
- MPelizzola
- SPretis
- MMGorski
- ATesi
- MJMorelli
- PBora
- MDoni
- AVerrecchia
- CTonelli
- GFagà
- VBianchi
- ARonchi
- DLow
- HMüller
- EGuccione
- SCampaner
- BAmati
-
- ISchlosser
- MHölzel
- RHoffmann
- HBurtscher
- FKohlhuber
- MSchuhmacher
- RChapman
- UHWeidle
- DEick
-
- CASchneider
- WSRasband
- KWEliceiri
-
- MSchuhmacher
- MSStaege
- APajic
- APolack
- UHWeidle
- GWBornkamm
- DEick
- FKohlhuber
-
- RSilberzahn
- ELUhlmann
- DPMartin
- PAnselmi
- FAust
- ECAwtrey
- ŠBahník
- FBai
- CBannard
- EBonnier
- RCarlsson
- FCheung
- GChristensen
- RClay
- MACraig
- ADalla Rosa
- LDam
- MHEvans
- FCervantes
- NFong
- MGamez-Djokic
- AGlenz
- SGordon-McKeon
- THeaton
- KHEriksson
- MHeene
- AHofelich Mohr
- FHögden
- KHui
- MJohannesson
- JKalodimos
- EKaszubowski
- DMKennedy
- RLei
- TALindsay
- SLiverani
- CRMadan
- DCMolden
- EMolleman
- RDMorey
- LBMulder
- BANijstad
- BPope
- NGPope
- JMPrenoveau
- FRink
- ERobusto
- HRoderique
- ASandberg
- ESchlueter
- FDSchönbrodt
- MFSherman
- SASommer
- KLSotak
- SMSpain
- CSpörlein
- TStafford
- LStefanutti
- STäuber
- JUllrich
- MVianello
- E-JWagenmakers
- MWitkowiak
- SYoon
- BANosek
-
- EFTrakhtenberg
- NPho
- KMHolton
- TWChittenden
- JLGoldberg
- LDong
-
- JCValentine
- ABiglan
- RFBoruch
- FGCastro
- LMCollins
- BRFlay
- SKellam
- EKMościcki
- SPSchinke
-
- WViechtbauer
-
- SWalz
- FLorenzin
- JMorton
- KEWiese
- BEyss
- SHerold
- LRycak
- HDumay-Odelot
- SKarim
- MBartkuhn
- FRoels
- TWüstefeld
- MFischer
- MTeichmann
- LZender
- CLWei
- OSansom
- EWolf
- MEilers